Legacy Document
Important: The information in this document is obsolete and should not be used for new development.
Important: The information in this document is obsolete and should not be used for new development.
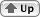


Converts a string from Unicode to the specified encoding.
pascal OSStatus ConvertFromUnicodeToText (
The ConvertFromUnicodeToText function converts a Unicode text string to the destination encoding you specify in the Unicode mapping structure that you pass to the function CreateUnicodeToTextInfo or CreateUnicodeToTextInfoByEncoding when you call them to obtain a Unicode converter object for the conversion process. You pass the returned object to ConvertFromUnicodeToText as the iUnicodeToTextInfo parameter.
In addition to converting the Unicode string, ConvertFromUnicodeToText can map offsets for style or font information from the source text string to the returned converted string. The converter reads the application-supplied offsets and returns the corresponding new offsets in the converted string. If you do not want font or style information offsets mapped to the resulting string, you should pass NULL for iOffsetArray and 0 (zero) for iOffsetCount.
Your application must allocate a buffer to hold the resulting converted string and pass a pointer to the buffer in the oOutputStr parameter. To determine the size of the output buffer to allocate, you should consider the size and content of the Unicode source string in relation to the type of encoding to which it will be converted. For example, for many encodings, such as MacRoman and Shift-JIS, the size of the returned string will be between half the size and the same size as the source Unicode string. However, for some encodings that are not Mac OS ones, such as EUC-JP, which has some 3-byte characters for Kanji, the returned string could be larger than the source Unicode string. For MacArabic and MacHebrew, the result will usually be less than half the size of the Unicode string.
This function modifies the contents of the Unicode converter object you passed as the iUnicodeToTextInfo parameter.
The function ConvertFromTextToUnicode