Not Recommended Document
Important: The information in this document is Not Recommended and should not be used for new development.
Current information on this Reference Library topic can be found here:
ADC Home > Reference Library > Technical Notes > Networking > Hardware & Drivers >
Important: The information in this document is Not Recommended and should not be used for new development.
Current information on this Reference Library topic can be found here:
|
Getting StartedQ What is STREAMS? A When written in upper case, STREAMS refers to a standard environment for loadable networking modules. This environment was first introduced as part of AT&T UNIX [UNIX is a registered trademark of UNIX Systems Laboratory, Inc., in the U.S. and other countries], but has since been ported to many platforms. Q So what is Open Transport? A Open Transport is an implementation of STREAMS on the Mac OS. OT contains a number of enhancements vis-a-vis a traditional STREAMS environment, but STREAMS lives at its core. Q What is Mentat Portable Streams? A Mentat Portable Streams (MPS) is a fast, portable implementation of STREAMS that is licensed to system vendors by Mentat. While MPS is compliant with the AT&T UNIX STREAMS at the API level, it contains many enhancements, both internal and external. Open Transport's STREAMS environment is based on MPS. Q I'm just getting started with STREAMS. What should I read? A There are a number of useful references that explain the STREAMS architecture in general:
The "Open Transport Module Developer Note" (part of the Open Transport SDK) describes the differences between a standard UNIX STREAMS implementation and the one provided by Open Transport. In general, the OT implementation is very close to UNIX, so if you're an experienced UNIX STREAMS programmer you will be in familiar territory. Open Transport Advanced Client Programming explains many of the low-level client programming interfaces required to test and plumb your STREAMS plug-ins under Open Transport. Another reference I find useful is UNIX
You should also keep on eye on the Open Transport web page, which contains news and information for Open Transport developers. In addition, there are a number of non-Apple STREAMS-related sites on the Internet, including:
Finally, you should join the OT mailing list, which is a mailing list dedicated to solving Open Transport programming questions, at all levels of experience. See the Apple mailing lists web page for instructions on how to join. Q What's the relationship between STREAMS and XTI? A XTI is a standard API for accessing network services. STREAMS is a standard way of implementing networking services. Traditionally machines running STREAMS support an XTI API, although it is possible to support other types of APIs. For example, Open Transport supports a standard XTI interface, an asynchronous XTI interface, and classic networking backward compatibility, all on top of STREAMS. Also, UNIX STREAMS implementations commonly support a Berkeley Sockets API on top of STREAMS. Q Isn't STREAMS slow? A A poorly implemented STREAMS framework can slow down STREAMS-based protocol stacks. This is not true of MPS. Actual detailed performance measurements of MPS on multiple platforms have shown MPS's overhead to be negligible, and have shown that Mentat's STREAMS-based TCP outperforms various BSD-based TCP implementations. STREAMS Modules and DriversQ I'm reading the STREAMS Modules and Driversbook described above and I can't make head or tail of it. Any suggestions? A I must admit
that it wasn't until my third attempt at reading
that book that I made any sense out of it. My
secret? I found that if you print out a copy of the
Q What is a "stream"? A In the most general definition, a stream (in lower case) is a connection oriented sequence of bytes sent between two processes. However, in the STREAMS environment, a stream normally refers to a connection between a client process and a network provider. For example, when you open a URL in a web browser, it creates a stream to the TCP module to transport connection information and data. A stream carries the implication of instance. For example, there is only one Ethernet driver but it can support many different streams. One stream might be used by AppleTalk, one by TCP, and yet another by a network sniffing program. Finally, a stream also implies a chain of modules, starting at the stream head and terminated at a driver. For example, if you open an endpoint "adsp,ddp,enet0", the system creates a new stream that looks like the one shown below. 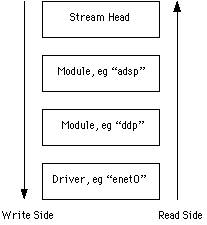 Any data that you write to that endpoint starts at the stream head and proceeds first to the "adsp" module. That module can pass the data downstream (in this case towards the "ddp") with or without modifying it, or swallow the data completely, or reply to the data with a message sent upstream. Q What is the stream head? A The stream head is part of the STREAMS kernel. It is responsible for managing all interaction between the client and the modules. It works in concert with client side libraries that implement the actual networking APIs. There are two keys areas of interaction: signals and memory copying. Signals are a mechanism whereby the
kernel can inform client code of certain events.
Typically this is used for events like the arrival
of data, but it is possible for modules to generate
signals directly by sending the Memory copying is the other main duty of the
stream head. When you call an API routine (such as
Because all data is transmitted between client and kernel using messages, there is only one point of entry between the client and the kernel. This means that STREAMS modules are not required to deal with client address spaces. This central location where the kernel accesses client memory decreases the risk of a protection violation on a protected memory system, and allows STREAMS modules to run in response to an interrupt without requiring a context switch. Of course, there are some complications. For
example, some API routines (especially
Q What's the difference between a module and a driver? AI asked this question when I was learning STREAMS and got the answer "A module can only be pushed, and a driver can only be opened." This answer is fundamentally correct, but it didn't help a lot at the time. The real answer is that there isn't a lot of difference between the two; modules and drivers have a very similar structure. In most cases, STREAMS documentation says "module" when it mean "module or driver". The big difference between a module and a driver is that a driver is the base of a stream. Streams pass through modules, but terminate at drivers. Thus modules must be pushed on top of an existing stream (because they need someone downstream of them), whereas drivers are always opened directly. The following picture shows multiple AppleTalk streams all based on top of one Ethernet driver. 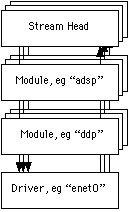 This is complicated by the existence of
multiplexing drivers. Multiplexing drivers
have both upper and lower interfaces. The upper
interface looks like a driver, that is, it can be
opened multiple times for multiple streams and
appears to be the end of those streams. However you
can also send a special For example, you might implement the IP module as a multiplexing driver. IP has multiple upper streams (i.e. client processes using IP) and multiple lower streams (i.e. hardware interfaces over which IP is running) but there is no one-to-one correspondence between these streams. IP uses one algorithm (routing) to determine the interface on which to forward outgoing packets. IP uses a second algorithm (protocol types) to determine which upper stream should receive incoming IP packets. The following picture shows three TCP streams connected to a IP multiplexing driver, which is in turn connected to link layer ports, one run directly through an Ethernet driver, and the other through another stream that connects a SLIP module to a serial port. 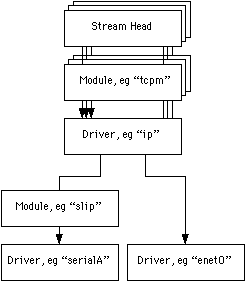
Q I've noticed Open Transport has an "ip" driver and an "ipm" module. Why do some modules also appear as drivers? A This is an implementation decision on the part of the module writer. In some cases, it's convenient to access a module as a module, and in other cases it's convenient to access it as a driver. In this specific case, the MPS IP module behaves differently depending on whether it is opened as a module or a driver. When OT is bringing up the TCP/IP networking stack, it first opens the "ip" driver. IP recognizes that this first connection, known as the control stream, is special, and responds to it in a special way. Later, when OT is bringing up interfaces under IP (e.g. an Ethernet card and a PPP link), it first opens the link-layer driver and then pushes the "ipm" module on top of it. Each time OT does this, the IP module recognizes this special case and prepares itself to handle this new interface. Finally, when a client process actually wants to access IP services, OT opens the "ip" driver to create a new stream to it for the client. STREAMS gives you a lot of flexibility, and the designers of MPS IP chose to use it. Q What is this
A The
One queue is designated the write-side queue. Data that the client sends to the stream is handled on the write-side queue. The other queue is the read-side queue. Data that the stream generates and sends to the client is handled on the read-side queue. Each queue has a put routine, which is called whenever a message is sent to the module. The put routine has the choice of sending the message on to the next module (with or without modification), temporarily queuing the message on the queue for processing later, replying to the message by queuing the reply on the other queue in the queue pair, or freeing the message. Each queue also has an optional service routine that is called when there is queued data to be processed. The service routine is optional because the module's put routine may be written in such a way that it never queues messages for later processing. Because these routines are specific to a queue, modules tend to contain two routines of each type, one for the read side and one for the write side. These routines are known as the read put routine, read service routine, write put routine, and write service routine. In addition, multiplexing drivers can have both upper and lower queue pairs, implying a total of eight entry points. When called, each of these routines is passed a
Q I'm executing in a read-side routine (either a put or service routine) and I need access to the write-side queue. How do I find it? A Queue structures
are actually allocated in memory as pairs, butted
up right next to each other, with the read queue
immediately preceding the write queue. Given that
Q How do I store global data in my module? AThe best way to store globals in your module is just to declare global variables. Because modules are shared libraries, you don't need to do anything special to access these globals. Note that these globals are shared across all instances of your module, i.e. all streams that run through your module.
If you want to store globals on a per-stream basis, you have to do a little more. The following snippet demonstrates the recommended technique.
The Open Transport Module Developer Note has a full description of the routines used in the above snippet. Q How do I synchronize access to my global data? A MPS
provides support for synchronizing access to global
or per-stream data. When you install your module,
you must fill out the
The legal values for the sync queue level are:
In the above list, sync queue levels are given
from least exclusive (
So, what does this mean in practical terms? Before OT calls your module (either the put routine or the service routine), it checks to see whether there is a thread of execution already running in your module. If there is, it checks the sync queue level of the module to see whether calling your module would be valid at this time. It uses these two factors to decide whether to call your module immediately, or queue the call for some later task to execute. The sync queue levels fall into two categories:
Of course, these mutual exclusion guarantees are for when STREAMS calls you, i.e. your open, close, put and service routines. If you are called by other sources (such as a hardware interrupts), you have to take additional measures to ensure data coherency. Of course, OT provides support for this too. See the Open Transport Module Developer Note for a description of the routines you can call from your hardware interrupt handler. In general, I recommend that you first use
Q I'm confused by the
A For the open and
close routines, STREAMS only looks at the read-side
Q How should I structure my STREAMS module? ASTREAMS modules have two primary entry points, the put routine and the service routine. In general, you should try to do all the work you can in your put routine. This is contradictory to most of the STREAMS documentation, and is an important factor in making your modules fast. Every time you use The alternative is to process the message in
your put routine and then immediately send the
message on to the next module (using
Of course you can still use Q How does flow control work? ASTREAMS flow control is quite hard to understand. The basic tenets of STREAMS flow control are:
Finally, there is one important hint for using flow control. In certain special case situations, such as constructing a sequence of messages, it may be extremely inconvenient to deal with flow control. At times like this, you always have the option of ignoring it. While not strictly legal, this will work and is unlikely to get you into trouble. But it is important that you deal with flow control in the general case, otherwise messages will pile up on queues, and STREAMS will run out of memory. Q Which should I use,
A STREAMS Modules and Drivers contains a number of code samples that look like:
This is an anachronism from UNIX STREAMS's support
of multi-processor (MP) systems. MPS STREAMS has
full support for MP built-in, so
Q I've notice that
some STREAMS routines return A The STREAMS internal routines were imported wholesale from UNIX and, in some cases, the prototypes do not match the semantics. In these cases, you should make sure to ignore the returned value. Q STREAMS Modules and Drivers talks a lot about bands. Is this of any use? A Not really. Some protocol modules (such as TCP and ADSP) have the concept of expedited data and typically these are supported using band 0 (normal data) and band 1 (expedited data). No one has ever found a use for all 255 bands! Also, note the band structures inside STREAMS are allocated as an array, so if you use more than one band, make sure you allocate them sequentially from 0. Otherwise you might find yourself using a lot more memory than you expect. Finally, you should remember that bands only
affect the order in which messages are queued, and
hence the order in which they are returned by
Q What fields of the
A There are a number of rules related to the fields in a queue:
The The functions can return the following errors:
Q The standard UNIX
STREAMS books do not contain any information about
the routines that begin with the prefix
A These are utilities routines provided by Mentat to make STREAMS programming easier. They are documented in the Open Transport Module Developer Note. I strongly recommend that you use these routines because they help cut down on silly programming errors. Messages and Memory AllocationQ Can I modify the message blocks that are passed to my module? A Yes, as long as
you are careful. To start with, you must
distinguish between message blocks
( The following fields of the Data blocks are slightly different. A single
data block can be referenced by multiple message
blocks, so you are only allowed to modify the
fields in the data block (or indeed its contents)
if you are the sole owner of the block. You
determine this by looking at the
If you wish to write to a read-only data block, you should copy the block using one of the allocation functions described below. The only field of the Q How do I allocate new messages within my module? A There are a lot
of techniques. If you just want to allocate a raw
message along with its data block, use the STREAMS
function
There are also a number of utilities routines for allocating TPI messages that you might find useful. These include:
See the Open Transport Module Developer Note for more details on these routines. Q Why do I get a link
error when I try to use
A It appears that someone forgot to export that routine. Fortunately, it's very easy to write you own version:
Q How do I reuse an existing message? A In writing a module, you often find yourself in the situation where you want to free a message and then allocate a new message in reply to the original message. In these cases, it's much better to reuse the first message rather than suffer the overhead of the freeing one message and allocating another. You can reuse a message block as long as both of the following conditions are true:
STREAMS guarantees that all control messages
generated by OT provides utility routines for reusing messages. The most general purpose one is:
This routine attempts to reuse the message pointed
to by There are also a number of utilities routines specific to TPI that you might find useful including:
See the Open Transport Module Developer Note for more details on these routines.
Q How much data is in a message? A If you just want
to know how much data there is in a single message
block, you can simply calculate Q How much space is there in a message? A If you just want
to know how much space is available in a single
message block, you can simply calculate
Q Are there any invariants that I can use to keep my message blocks straight? A Yes. The invariants are that: mp->b_datap->db_base < mp->b_datap->db_lim mp->b_datap->db_base <= mp->b_rptr < mp->b_datap->db_lim mp->b_datap->db_base <= mp->b_wptr <= mp->b_datap->db_lim mp->b_rptr <= mp->b_wptr These invariants imply that:
Q A lot of STREAMS
allocation functions (e.g. A At the moment, STREAMS is defined to ignore these values. There are two reasonable approaches:
I recommend the first approach. Q What do I do when an allocation fails? A The approach you take depends on the type of module you are writing. If you are writing a module that provides an unreliable service (such as a DLPI device driver), the best thing to do when you run out of memory is to just drop the current packet on the floor. Because you are providing an unreliable service, the upper-layer protocol is required to implement some error correction anyway, so there's no point complicating your module with intricate error handling. If you're writing a reliable service, you must
be prepared to deal with running out of memory.
Your primary weapon should be the
See the Open Transport
Module Developer Note for more details on
Transport Provider Interface (TPI)Q I'm writing a STREAMS TPI module or driver. Where should I start? A The best book to read is STREAMS Modules and Drivers. In terms of sample code, there are a number of samples to look at:
None of these samples are perfect, but they do give a flavour of what STREAMS programming is like. Q I'm receiving a TPI message. Can I reuse that message to send the ACK? A See the question How do I reuse an existing message? Q I'm writing a TPI
module and I successfully respond to a
A The short answer
is that you need to send a connection confirmation
message ( The long answer is that you need to study the
TPI specification more closely, paying special
attention to the state diagrams. When your module
is in I find it useful to think of the
Q The TPI
specification says that the address to connect to
is pointed to by the A There are two aspects to this question. First, how do Open Transport clients provide address information. Second, how does Open Transport translate that client representation into a TPI message. Open Transport uses a standard format for
address information that's based on the
The
These are distinguished by the first two bytes. An
When you call an OT API routine and pass in an address like this, OT simply copies the entire address into a message block without interpreting it. When the message reaches the appropriate TPI module, that module is responsible for interpreting the specified address. It can determine that the address is in the appropriate format simply by looking at the first two bytes of the address buffer. The snippet of code in the next Q&A shows how to do this. Q TPI messages often contain "offset" and "count" parameters to reference variable length data. Every time I access these, I find myself dying the 'death of a thousand pointers'. Is there a better way? A I'm glad you asked. MPS provides two useful utility routines that you can call to access these variable length structures. There prototypes are:
If you have a simple TPI message (one with a single
message block), you can call
If there's a possibility that the data you're
looking for is not in the first message block of
the TPI message, you can use
The following snippet shows how you can use
Q In my TPI module I send data messages but they never arrive on the wire/at the client. Any ideas? A You have most
probably forgotten to set the Data Link Provider Interface (DLPI)Q I'm writing a STREAMS DLPI driver. Where should I start? A You should start with one of the generic STREAMS references listed above, then continue with the following Open Transport-specific material.
Q What's this stuff about connection-oriented DLPI drivers? A I have no idea!
As far as the OT mainstream is concerned, all DLPI
drivers are connection-less
( Q I'm writing the
code to fill out the A Unless you have
an overriding reason to use PPAs, you should return
Q What is this stuff about major and minor device numbers? A The short answer is: an anachronism from UNIX. Major device numbers represent the device driver controlling a device. This is traditionally an index into a table of drivers maintained internally by STREAMS. Under Open Transport, drivers are loaded into this table on demand, so there's no way you can know what major device number your driver is going to get. Minor device numbers are used to distinguish between multiple functions controlled by a single device driver, for example, multiple serial ports controlled by the serial port driver. However, this definition breaks down in the face of networking, even on UNIX systems. It turns out that minor device numbers are used
to distinguish between different streams connected
to a driver. Each stream is given a unique minor
device number by the driver's open routine. This is
accomplished by means of the
So how does this affect you? It doesn't! If you
call SummaryOpen Transport is based on an industry standard STREAMS networking kernel. Open Transport STREAMS is documented in a number of UNIX books. and in the Open Transport Module Developer Note . This Note answers some Frequently Asked Questions about issues that are not adequately covered in the other documentation. ReferencesProgrammer's Guide: STREAMS, UNIX System V Release 4, UNIX Press, ISBN 0-13-02-0660-1 STREAMS Modules and Drivers, UNIX System V Release 4.2, UNIX Press, ISBN 0-13-066879-6 "Open Transport Module Developer Note" (part of the Open Transport SDK) UNIX "man" pages for "putmsg", "getmsg", etc. Open Transport programmers mailing list Change History
Downloadables
|
|