Cocoa Objects
To say that Cocoa is object-oriented is to invite the question: What is a Cocoa object? This section describes what is distinctive about Objective-C objects and what advantages the language brings to software development. It also shows you how to use Objective-C to send messages to objects and how to handle return values from those messages. (Objective-C is an elegantly simple language, so this is not too hard to do.) This section also describes the root class, NSObject, and explains how to use its programmatic interface to create objects, introspect them, and manage object life cycles
In this section:
A Simple Cocoa Command-Line Tool
Object-Oriented Programming With Objective-C
The Root Class
Object Retention and Disposal
Object Creation
Introspection
Object Mutability
Class Clusters
Creating a Singleton Instance
A Simple Cocoa Command-Line Tool
Let’s begin with a simple command-line program created using the Foundation framework for Mac OS X. Given a series of arbitrary words as arguments, the program removes redundant occurrences, sorts the remaining list of words in alphabetical order, and prints the list to standard output. Listing 2-1 shows a typical execution of this program.
Listing 2-1 Output from a simple Cocoa tool
localhost> SimpleCocoaTool a z c a l q m z |
a |
c |
l |
m |
q |
z |
Listing 2-2 shows the code for an Objective-C version of this program.
Listing 2-2 Cocoa code for a uniquing and sorting tool
#import <Foundation/Foundation.h> |
int main (int argc, const char * argv[]) { |
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; |
NSArray *args = [[NSProcessInfo processInfo] arguments]; |
NSCountedSet *cset = [[NSCountedSet alloc] initWithArray:args]; |
NSArray *sorted_args = [[cset allObjects] |
sortedArrayUsingSelector:@selector(compare:)]; |
NSEnumerator *enm = [sorted_args objectEnumerator]; |
id word; |
while (word = [enm nextObject]) { |
printf("%s\n", [word UTF8String]); |
} |
[cset release]; |
[pool release]; |
return 0; |
} |
This code creates and uses several objects: an autorelease pool for memory management, collection objects (arrays and a set) for “uniquing” and sorting the specified words, and an enumerator object for iterating through the elements in the final array and printing them to standard output.
The first thing you probably notice about this code is that it is short, perhaps much shorter than a typical ANSI C version of the same program. Although much of this code might look strange to you, many of its elements are familiar ANSI C. These include assignment operators, control-flow statements (while), calls to C-library routines (printf), primitive scalar types, and so on. Objective-C obviously has ANSI C underpinnings.
The rest of this chapter examines the Objective-C elements of this code, using them as examples in discussions on subjects ranging from the mechanics of message-sending to the techniques of memory management. If you haven’t seen Objective-C code before, the code in the example might seem formidably convoluted and obscure, but that impression will melt away soon. Objective-C is actually a simple, elegant programming language that is easy to learn and intuitive to program with.
Object-Oriented Programming With Objective-C
Cocoa is pervasively object-oriented, from its paradigms and mechanisms to its event-driven architecture. Objective-C, the development language for Cocoa, is thoroughly object-oriented too, despite its grounding in ANSI C. It provides runtime support for message dispatch and specifies syntactical conventions for defining new classes. Objective-C supports most of the abstractions and mechanisms found in other object-oriented languages such as C++ and Java. These include inheritance, encapsulation, reusability, and polymorphism.
But Objective-C is different from these other object-oriented languages, often in important ways. For example, Objective-C, unlike C++, doesn’t allow operator overloading, templates, or multiple inheritance.
Although Objective-C doesn’t have these features, its strengths as an object-oriented programming language more than compensate. What follows is an exploration of the special capabilities of Objective-C.
Further Reading: Much of this section summarizes information from the definitive guide to Objective-C, The Objective-C 2.0 Programming Language. Consult this document for a detailed and comprehensive description of Objective-C.
The Objective-C Advantage
If you’re a procedural programmer new to object-oriented concepts, it might help at first to think of an object as essentially a structure with functions associated with it. This notion is not too far off the reality, particularly in terms of runtime implementation.
Every Objective-C object hides a data structure whose first member—or instance variable—is the “isa pointer.” (Most remaining members are defined by the object’s class and superclasses.) The isa pointer, as the name suggests, points to the object’s class, which is an object in its own right (see Figure 2-1) and is compiled from the class definition. The class object maintains a dispatch table consisting essentially of pointers to the methods it implements; it also holds a pointer to its superclass, which has its own dispatch table and superclass pointer. Through this chain of references, an object has access to the method implementations of its class and all its superclasses (as well as all inherited public and protected instance variables). The isa pointer is critical to the message-dispatch mechanism and to the dynamism of Cocoa objects.
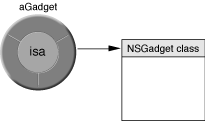
This peek behind the object facade gives a highly simplified view of what happens in the Objective-C runtime to enable message-dispatch, inheritance, and other facets of general object behavior. But this information is essential to understanding the major strength of Objective-C, its dynamism.
The Dynamism of Objective-C
Objective-C is a very dynamic language. Its dynamism frees a program from compile-time and link-time constraints and shifts much of the responsibility for symbol resolution to runtime, when the user is in control. Objective-C is more dynamic than other programming languages because its dynamism springs from three sources:
For dynamic typing, Objective-C introduces the id data type, which can represent any Cocoa object. A typical use of this generic object type is shown in this part of the code example from Listing 2-2:
id word; |
while (word = [enm nextObject]) { |
// etc.... |
The id data type makes it possible to substitute any type of object at runtime. You can thereby let runtime factors dictate what kind of object is to be used in your code. Dynamic typing permits associations between objects to be determined at runtime rather than forcing them to be encoded in a static design. Static type checking at compile time may ensure stricter data integrity, but in exchange for that integrity, dynamic typing gives your program much greater flexibility. And through object introspection (for example, asking a dynamically typed, anonymous object what its class is) you can still verify the type of an object at runtime and thus validate its suitability for a particular operation. (Of course, you can always statically check the types of objects when you need to.)
Dynamic typing gives substance to dynamic binding, the second kind of dynamism in Objective-C. Just as dynamic typing defers the resolution of an object’s class membership until runtime, dynamic binding defers the decision of which method to invoke until runtime. Method invocations are not bound to code during compilation, but only when a message is actually delivered. With both dynamic typing and dynamic binding, you can obtain different results in your code each time you execute it. Runtime factors determine which receiver is chosen and which method is invoked.
The runtime’s message-dispatch machinery enables dynamic binding. When you send a message to a dynamically typed object, the runtime system uses the receiver’s isa pointer to locate the object’s class, and from there the method implementation to invoke. The method is dynamically bound to the message. And you don’t have to do anything special in your Objective-C code to reap the benefits of dynamic binding. It happens routinely and transparently every time you send a message, especially one to a dynamically typed object.
Dynamic loading, the final type of dynamism, is a feature of Cocoa that depends on Objective-C for runtime support. With dynamic loading, a Cocoa program can load executable code and resources as they’re needed instead of having to load all program components at launch time. The executable code (which is linked prior to loading) often contains new classes that become integrated into the runtime image of the program. Both code and localized resources (including nib files) are packaged in bundles and are explicitly loaded with methods defined in Foundation’s NSBundle class.
This “lazy-loading” of program code and resources improves overall performance by placing lower memory demands on the system. Even more importantly, dynamic loading makes applications extensible. You can devise a plug-in architecture for your application that allows you and other developers to customize it with additional modules that the application can dynamically load months or even years after the application is released. If the design is right, the classes in these modules will not clash with the classes already in place because each class encapsulates its implementation and has its own name space.
Extensions to the Objective-C Language
Objective-C features two extensions to the base language that are powerful tools in software development: categories and protocols. Some extensions introduce different techniques for declaring methods and associating them with a class. Others offer convenient ways to declare and access object properties, enumerate quickly over collections, handle exceptions, and perform other tasks.
Categories
Categories give you a way to add methods to a class without having to make a subclass. The methods in the category become part of the class type (within the scope of your program) and are inherited by all the class’s subclasses. There is no difference at runtime between the original methods and the added methods. You can send a message to any instance of the class (or its subclasses) to invoke a method defined in the category.
Categories are more than a convenient way to add behavior to a class. You can also use categories to compartmentalize methods, grouping related methods in different categories. Categories can be particularly handy for organizing large classes; you can even put different categories in different source files if, for instance, there are several developers working on the class.
You declare and implement a category much as you do a subclass. Syntactically, the only difference is the name of the category, which follows the @interface or @implementation directive and is put in parentheses. For example, say you want to add a method to the NSArray class that prints the description of the collection in a more structured way. In the header file for the category, you would write declaration code similar to the following:
#import <Foundation/NSArray.h> // if Foundation not already imported |
@interface NSArray (PrettyPrintElements) |
- (NSString *)prettyPrintDescription; |
@end |
Then in the implementation file you’d write code such as:
#import "PrettyPrintCategory.h" |
@implementation NSArray (PrettyPrintElements) |
- (NSString *)prettyPrintDescription { |
// implementation code here... |
} |
@end |
There are some limitations to categories. You cannot use a category to add any new instance variables to the class. Although a category method can override an existing method, it is not recommended that you do so, especially if you want to augment the current behavior. One reason for this caution is that the category method is part of the class’s interface, and so there is no way to send a message to super to get the behavior already defined by the class. If you need to change what an existing method of a class does, it is better to make a subclass of the class.
You can define categories that add methods to the root class, NSObject. Such methods are available to all instances and class objects that are linked into your code. Informal protocols—the basis for the Cocoa delegation mechanism—are declared as categories on NSObject. This wide exposure, however, has its dangers as well as its uses. The behavior you add to every object through a category on NSObject could have consequences that you might not be able to anticipate, leading to crashes, data corruption, or worse.
Protocols
The Objective-C extension called a protocol is very much like an interface in Java. Both are simply a list of method declarations publishing an interface that any class can choose to implement. The methods in the protocol are invoked by messages sent by an instance of some other class.
The main value of protocols is that they, like categories, can be an alternative to subclassing. They yield some of the advantages of multiple inheritance in C++, allowing sharing of interfaces (if not implementations). A protocol is a way for a class to declare an interface while concealing its identity. That interface may expose all or (as is usually the case) only a range of the services the class has to offer. Other classes throughout the class hierarchy, and not necessarily in any inheritance relationship (not even to the root class), can implement the methods of that protocol and so access the published services. With a protocol, even classes that have no knowledge of another’s identity (that is, class type) can communicate for the specific purpose established by the protocol.
There are two types of protocols: formal and informal. Informal protocols were briefly introduced in “Categories.” These are categories on NSObject; as a consequence, every object with NSObject as its root object (as well as class objects) implicitly adopts the interface published in the category. To use an informal protocol, a class does not have to implement every method in it, just those methods it’s interested in. For an informal protocol to work, the class declaring the informal protocol must get a positive response to a respondsToSelector: message from a target object before sending that object the protocol message. (If the target object did not implement the method there would be a runtime exception.)
Formal protocols are usually what is designated by “protocol” in Cocoa. They allow a class to formally declare a list of methods that are an interface to a vended service. The Objective-C language and runtime system supports formal protocols; the compiler can check for types based on protocols, and objects can introspect at runtime to verify conformance to a protocol. Formal protocols have their own terminology and syntax. The terminology is different for provider and client:
A provider (which usually is a class) declares the formal protocol.
A client class adopts a formal protocol, and by doing so agrees to implement all required methods of the protocol.
A class is said to conform to a formal protocol if it adopts the protocol or inherits from a class that adopts it. (Protocols are inherited by subclasses.)
Both the declaration and the adoption of a protocol have their own syntactical forms in Objective-C. To declare a protocol you must use the @protocol compiler directive. The following example shows the declaration of the NSCoding protocol (in the Foundation framework’s header file NSObject.h).
@protocol NSCoding |
- (void)encodeWithCoder:(NSCoder *)aCoder; |
- (id)initWithCoder:(NSCoder *)aDecoder; |
@end |
Objective-C 2.0 adds a refinement to formal protocols by giving you the option of declaring optional protocol methods as well as required ones. In Objective-C 1.0, the adopter of a protocol had to implement all methods of the protocol. In Objective-C 2.0 protocol methods are still implicitly required, and can be specifically marked as such using the @required directive. But you can also mark blocks of protocol methods for optional implementation using the @optional directive; all methods declared after this directive, unless there is an intervening @required, can be optionally implemented. Consider these declarations:
@protocol MyProtocol |
// implementation this method is required implicitly |
- (void)requiredMethod; |
@optional |
// implementation of these methods is optional |
- (void)anOptionalMethod; |
- (void)anotherOptionalMethod; |
@required |
// implementation of this method is required |
- (void)anotherRequiredMethod; |
@end |
The class that declares the protocol methods typically does not implement those methods; however, it should invoke these methods in instances of the class that conforms to the protocol. Before invoking optional methods, it should verify that they’re implemented using the respondsToSelector: method.
A class adopts a protocol by specifying the protocol, enclosed by angle brackets, at the end of its @interface directive, just after the superclass. A class can adopt multiple protocols by delimiting them with commas. This is how the Foundation NSData class adopts three protocols.
@interface NSData : NSObject <NSCopying, NSMutableCopying, NSCoding> |
By adopting these protocols, NSData commits itself to implementing all required methods declared in the protocols. It may also choose to implement methods marked with the @optional directive. Categories can also adopt protocols, and their adoption becomes part of the definition of their class.
Objective-C types classes by the protocols they conform to as well as the classes they inherit from. You can check if a class conforms to a particular protocol by sending it a conformsToProtocol: message:
if ([anObject conformsToProtocol:@protocol(NSCoding)]) { |
// do something appropriate |
} |
In a declaration of a type—a method, instance variable, or function—you can specify protocol conformance as part of the type. You thus get another level of type checking by the compiler, one that’s more abstract because it’s not tied to particular implementations. You use the same syntactical convention as for protocol adoption: Put the protocol name between angle brackets to specify protocol conformance in the type. You often see the dynamic object type, id, used in these declarations, for example:
- (void)draggingEnded:(id <NSDraggingInfo>)sender; |
Here the object referred to in the argument can be of any class type, but it must conform to the NSDraggingInfo protocol.
Cocoa provides several examples of protocols other than the ones shown so far. An interesting one is the NSObject protocol. Not surprisingly, the NSObject class adopts it, but so does the other root class, NSProxy. Through the protocol, the NSProxy class can interact with the parts of the Objective-C runtime essential to reference counting, introspection, and other basic aspects of object behavior.
Declared Properties
In the object modeling design pattern (see “Object Modeling”) objects have properties. Properties consist of an object’s attributes, such as title and color, and an object’s relationships with other objects. In traditional Objective-C code, you define properties by declaring instance variables and, to enforce encapsulation, by implementing accessor methods to get and set the values of those variables. This a tedious and error-prone task, especially when memory management is a concern (see “Storing and Accessing Properties”).
Objective-C 2.0, which was introduced in Mac OS X version 10.5, offers a syntax for declaring properties and specifying how they are to be accessed. Declaring a property becomes a kind of shorthand for declaring a setter and getter method for the property. With properties, you no longer have to implement accessor methods. Direct access to property values is also available through a new dot-notation syntax. There are three aspects to the syntax of properties: declaration, implementation, and access.
You can declare properties wherever methods can be declared in a class, category, or protocol declarative section. The syntax for declaring properties is:
@property(attributes...)type propertyName
where attributes are one or more optional attributes (comma-separated if multiple) that affect how the compiler stores instance variables and synthesizes accessor methods. The type element specifies an object type, declared type, or scalar type, such as id, NSString *, NSRange, or float. The property must be backed by an instance variable of the same type and name.
The possible attributes in a property declaration are the following:
Attribute | Effect |
|---|---|
| Specifies the names of getter and setter accessor methods (see “Storing and Accessing Properties.”) You specify these attributes when you are implementing your own accessor methods and want to control their names. |
| Indicates that the property can only be read from, not written to. The compiler does not synthesize a setter accessor or allow a non-synthesized one to be called. |
| Indicates that the property can be read from and written to. This is the default if |
| Specifies that simple assignment should be used in the implementation of the setter; this is the default. If properties are declared in a non-garbage-collected program, you must specify |
| Specifies that |
| Specifies that |
| Specifies that accessor methods are synthesized as nonatomic. By default, all synthesized accessor methods are atomic: a getter method is guaranteed to return a valid value, even when other threads are executing simultaneously. For a discussion of atomic versus nonatomic properties, especially with regard to performance, see “Declared Properties“ in The The Objective-C 2.0 Programming Language. |
If you specify no attributes and specify @synthesize for the implementation, the compiler synthesizes getter and setter methods for the property that use simple assignment and that have the forms propertyName for the getter and setPropertyName: for the setter.
In the @implementation blocks of a class definition, you can use the @dynamic and @synthesize directives to control whether the compiler synthesizes accessor methods for particular properties. Both directives have the same general syntax:
@dynamicpropertyName [,propertyName2...];@synthesizepropertyName [,propertyName2...];
The @dynamic directive tells the compiler that you are implementing accessor methods for the property, either directly or dynamically (such as when dynamically loading code). The @synthesize directive, on the other hand, tells the compiler to synthesize the getter and setter methods if they do not appear in the @implementation block. The syntax for @synthesize also includes an extension that allows you to name a property differently from its instance-variable storage. Consider, for example, the following statement:
@synthesize title, directReports, role = jobDescrip; |
This tells the computer to synthesize accessor methods for properties title, directReports, and role, and to use the jobDescrip instance variable to back the role property.
Finally, the Objective-C properties feature supports a simplified syntax for accessing (getting and setting) properties through the use of dot notation and simple assignment. A few examples suffice to show how easy it is to get the values of properties and set them using this syntax:
NSString *title = employee.title; // assigns employee title to local variable |
employee.ID = "A542309"; // assigns literal string to employee ID |
// gets last name of this employee's manager |
NSString *lname = employee.manager.lastName; |
Note that dot-notation syntax works only for attributes and simple one-to-one relationships, not to-many relationships.
Further Reading: To learn more about declared properties, read “Declared Properties“ in The Objective-C 2.0 Programming Language.
Fast Enumeration
Fast enumeration is a language feature introduced in Objective-C 2.0 that gives you a concise syntax for efficient enumeration of collections. It is much faster than the traditional use of NSEnumerator objects to iterate through arrays, sets, and dictionaries. Moreover, it ensures safe enumeration by including a mutation guard to prevent modification of a collection during enumeration. (An exception is thrown if a mutation is attempted.)
The syntax for fast enumeration is similar to that used in scripting languages such as Perl and Ruby; there are two supported versions:
for(type newVariableinexpression) {statements}
and
type existingVariable
;for(existingVariableinexpression) {statements}
expression must evaluate to an object whose class conforms to the NSFastEnumeration protocol. The fast-enumeration implementation is shared between the Objective-C runtime and the Foundation framework. Foundation declares the NSFastEnumeration protocol, and the Foundation collection classes—NSArray, NSDictionary, and NSSet—and the NSEnumerator class adopt the protocol. Other classes that hold collections of other objects, including custom classes, may adopt NSFastEnumeration to take advantage of this feature.
The following snippet of code illustrates how you might use fast enumeration with NSArray and NSSet objects:
NSArray *array = [NSArray arrayWithObjects: |
@"One", @"Two", @"Three", @"Four", nil]; |
for (NSString *element in array) { |
NSLog(@"element: %@", element); |
} |
NSSet *set = [NSSet setWithObjects: |
@"Alpha", @"Beta", @"Gamma", @"Delta", nil]; |
NSString *setElement; |
for (setElement in set) { |
NSLog(@"element: %@", setElement); |
} |
Further Reading: To find out more about fast enumeration, including how a custom collection class can take advantage of this feature, see “Fast Enumeration“ in The Objective-C 2.0 Programming Language.
Using Objective-C
The way work gets done in an object-oriented program is through messages; one object sends a message to another object. Through the message, the sending object requests something from the receiving object (receiver). It requests that the receiver perform some action, return some object or value, or do both things.
Objective-C adopts a unique syntactical form for messaging. Take the following statement from the SimpleCocoaTool code in Listing 2-2:
NSEnumerator *enm = [sorted_args objectEnumerator]; |
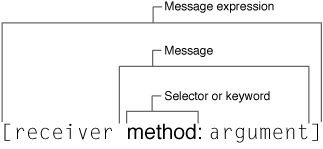
The message expression is on the right side of the assignment, enclosed by the square brackets. The left-most item in the message expression is the receiver, a variable or expression representing the object to which the message is sent. In this case, the receiver is sorted_args, an instance of the NSArray class. Following the receiver is the message proper, in this case objectEnumerator. (For now, we are going to focus on message syntax and not look too deeply into what this and other messages in SimpleCocoaTool actually do.) The message objectEnumerator invokes a method of the sorted_args object named objectEnumerator, which returns a reference to an object that is held by the variable enm on the left side of the assignment. This variable is statically typed as an instance of the NSEnumerator class. You can diagram this statement as:
However, this diagram is simplistic and not really accurate. A message consists of a selector name and the parameters of the message. The Objective-C runtime uses a selector name, such as objectEnumerator above, to look up a selector in a table in order to find the method to invoke. A selector is a unique identifier that represents a method and that has a special type, SEL. Because it’s so closely related, the selector name used to look up a selector is frequently called a selector as well. The above statement thus is more correctly shown as:
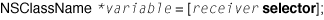
Messages often have parameters, or arguments. A message with a single argument affixes a colon to the selector name and puts the argument right after the colon. This construct is called a keyword ; a keyword ends with a colon, and an argument follows the colon. Thus we could diagram a message expression with a single argument (and assignment) as the following:
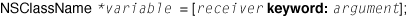
If a message has multiple arguments, the selector has multiple keywords. A selector name includes all keywords, including colons, but does not include anything else, such as return type or parameter types. A message expression with multiple keywords (plus assignment) could be diagrammed as follows:
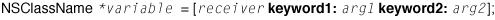
As with function parameters, the type of an argument must match the type specified in the method declaration. Take as an example the following message expression from SimpleCocoaTool:
NSCountedSet *cset = [[NSCountedSet alloc] initWithArray:args]; |
Here args, which is also an instance of the NSArray class, is the argument of the message named initWithArray:.
The initWithArray: example cited above is interesting in that it illustrates nesting. With Objective-C, you can nest one message inside another message; the object returned by one message expression is used as the receiver by the message expression that encloses it. So to interpret nested message expressions, start with the inner expression and work your way outward. The interpretation of the above statement would be:
The
allocmessage is sent to theNSCountedSetclass, which creates (by allocating memory for it) an uninitialized instance of the class.The
initWithArray:message is sent to the uninitialized instance, which initializes itself with the arrayargsand returns a reference to itself.
Next consider this statement from the main routine of SimpleCocoaTool:
NSArray *sorted_args = [[cset allObjects] sortedArrayUsingSelector:@selector(compare:)]; |
What’s noteworthy about this message expression is the argument of the sortedArrayUsingSelector: message. This argument requires the use of the @selector compiler directive to create a selector to be used as an argument.
Let’s pause a moment to review message and method terminology. A method is essentially a function defined and implemented by the class of which the receiver of a message is a member. A message is a selector name (perhaps consisting of one of more keywords) along with its arguments; a message is sent to a receiver and this results in the invocation (or execution) of the method. A message expression encompasses both receiver and message. Figure 2-2 depicts these relationships.
Objective-C uses a number of defined types and literals that you won’t find in ANSI C. In some cases, these types and literals replace their ANSI C counterparts. Table 2-1 describes a few of the important ones, including the allowable literals for each type.
Type | Description and literal |
|---|---|
| The dynamic object type. Its negative literal is |
| The dynamic class type. Its negative literal is |
| The data type ( |
| A Boolean type. The literal values are |
In your program’s control-flow statements, you can test for the presence (or absence) of the appropriate negative literal to determine how to proceed. For example, the following while statement from the SimpleCocoaTool code implicitly tests the word object variable for the presence of a returned object (or, in another sense, the absence of nil):
while (word = [enm nextObject]) { |
printf("%s\n", [word UTF8String]); |
} |
In Objective-C, you can often send a message to nil with no ill effects. Return values from messages sent to nil are guaranteed to work as long as what is returned is typed as an object.
One final thing to note about the SimpleCocoaTool code is something that is not readily apparent if you’re new to Objective-C. Compare this statement:
NSEnumerator *enm = [sorted_args objectEnumerator]; |
with this one:
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init]; |
On the surface, they seem to do identical things; both return a reference to an object. However there is an important semantic difference (for memory-managed code) that has to do with the ownership of the returned object, and hence the responsibility for freeing it. In the first statement, the SimpleCocoaTool program does not own the returned object. In the second statement, the program creates the object and so owns it. The last thing the program does is to send the release message to the created object, thus freeing it. The only other explicitly created object (the NSCountedSet instance) is also explicitly released at the end of the program. For a summary of the memory-management policy for object ownership and disposal, and the methods to use to enforce this policy, see “How Memory Management Works”.
The Root Class
Just by themselves, the Objective-C language and runtime are not enough to construct even the simplest object-oriented program, at least not easily. Something is still missing: a definition of the fundamental behavior and interface common to all objects. A root class supplies that definition.
A root class is so-called because it lies at the root of a class hierarchy—in this case, the Cocoa class hierarchy. The root class inherits from no other class, and all other classes in the hierarchy ultimately inherit from it. Along with the Objective-C language, the root class is primarily where Cocoa directly accesses and interacts with the Objective-C runtime. Cocoa objects derive the ability to behave as objects in large part from the root class.
Cocoa supplies two root classes: NSObject and NSProxy. Cocoa defines the latter class, an abstract superclass, for objects that act as stand-ins for other objects; thus NSProxy is essential in the distributed objects architecture. Because of this specialized role, NSProxy appears infrequently in Cocoa programs. When Cocoa developers refer to a root or base class, they almost always mean NSObject.
This section looks at NSObject, how it interacts with the runtime, and the basic behavior and interface it defines for all Cocoa objects. Primary among these are the methods it declares for allocation, initialization, memory management, introspection, and runtime support. These concepts are fundamental to an understanding of Cocoa.
NSObject
NSObject is the root class of most Objective-C class hierarchies; it has no superclass. From NSObject, other classes inherit a basic interface to the run-time system for the Objective-C language, and its instances obtain their ability to behave as objects.
Although it is not strictly an abstract class, NSObject is virtually one. By itself, an NSObject instance cannot do anything useful beyond being a simple object. To add any attributes and logic specific to your program, you must create one or more classes inheriting from NSObject or from any other class derived from NSObject.
NSObject adopts the NSObject protocol (see “Root Class—and Protocol”). The NSObject protocol allows for multiple root objects. For example, NSProxy, the other root class, does not inherit from NSObject but adopts the NSObject protocol so that it shares a common interface with other Objective-C objects.
Root Class—and Protocol
NSObject is the name not only of a class but of a protocol. Both are essential to the definition of an object in Cocoa. The NSObject protocol specifies the basic programmatic interface required of all root classes in Cocoa; thus not only the NSObject class adopts the identically named protocol, but the other Cocoa root class, NSProxy, adopts it as well. The NSObject class further specifies the basic programmatic interface for any Cocoa object that is not a proxy object.
A protocol such as NSObject is used in the overall definition of Cocoa objects (rather than including those protocol methods in the class interface) to make multiple root classes possible. Each root class shares a common interface, as defined by the protocols they adopt.
In another sense, NSObject is not the only “root” protocol. Although the NSObject class does not formally adopt the NSCopying, NSMutableCopying, and NSCoding protocols, it declares and implements methods related to those protocols. (Moreover, the NSObject.h header file, which contains the definition of the NSObject class, also contains the definitions of all four protocols mentioned above.) Object copying, encoding, and decoding are fundamental aspects of object behavior. Many, if not most, subclasses are expected to adopt or conform to these protocols.
Note: Other Cocoa classes can (and do) add methods to NSObject through categories. These categories are often informal protocols used in delegation; they permit the delegate to choose which methods of the category to implement. However, these categories on NSObject are not considered part of the fundamental object interface.
Overview of Root-Class Methods
The NSObject root class, along with the adopted NSObject protocol and other “root” protocols, specify the following interface and behavioral characteristics for all non-proxy Cocoa objects:
Allocation, initialization, and duplication. Some methods of
NSObject(including some from adopted protocols) deal with the creation, initialization, and duplication of objects:The
allocandallocWithZone:methods allocate memory for an object from a memory zone and set the object to point to its runtime class definition.The
initmethod is the prototype for object initialization, the procedure that sets the instance variables of an object to a known initial state. The class methodsinitializeandloadgive classes a chance to initialize themselves.newis a convenience method that combines simple allocation and initialization.The
copyandcopyWithZone:methods make copies of any object that is a member of a class implementing these methods (from the NSCopying protocol); themutableCopyandmutableCopyWithZone:(defined in theNSMutableCopyingprotocol) are implemented by classes that want to make mutable copies of their objects.
See “Object Creation” for more information.
Object retention and disposal. The following methods are particularly important to an object-oriented program that uses the traditional, and explicit, form of memory management:
The
retainmethod increments an object’s retain count.The
releasemethod decrements an object’s retain count.The
autoreleasemethod also decrements an object’s retain count, but in a deferred fashion.The
retainCountmethod returns an object’s current retain count.The
deallocmethod is implemented by class to release its objects’ instance variables and free dynamically allocated memory.
See the “How Memory Management Works” for more information about explicit memory management.
Introspection and comparison. Many
NSObjectmethods enable you to make runtime queries about an object. These introspection methods help to discover an object’s position in the class hierarchy, determine whether it implements a certain method, and test whether it conforms to a specific protocol. Some of these are class methods only.The
superclassandclassmethods (class and instance) return the receiver’s superclass and class, respectively, asClassobjects.You can determine the class membership of objects with the methods
isKindOfClass:andisMemberOfClass:; the latter method is for testing whether the receiver is an instance of the specified class. The class methodisSubclassOfClass:tests class inheritance.The
respondsToSelector:method tests whether the receiver implements a method identified by a selector. The class methodinstancesRespondToSelector:tests whether instances of a given class implement the specified method.The
conformsToProtocol:method tests whether the receiver (object or class) conforms to a given protocol,.The
isEqual:andhashmethods are used in object comparison.The
descriptionmethod allows an object to return a string describing its contents; this output is often used in debugging (“print object” command) and by the “%@” specifier for objects in formatted strings.
See “Introspection” for more information.
Object encoding and decoding. The following methods pertain to object encoding and decoding (as part of the archiving process):
The
encodeWithCoder:andinitWithCoder:methods are the sole members of the NSCoding protocol. The first allows an object to encode its instance variables and the second enables an object to initialize itself from decoded instance variables.The NSObject class declares other methods related to object encoding:
classForCoder,replacementObjectForCoder:, andawakeAfterUsingCoder:.
See Archives and Serializations Programming Guide for Cocoa for further information.
Message forwarding. The
forwardInvocation:and related methods permit an object to forward a message to another object.Message dispatch. A set of methods beginning with
performSelector...allow you to dispatch messages after a specified delay and to dispatch messages (synchronously or asynchronously) from a secondary thread to the main thread.
NSObject has several other methods, including class methods for versioning and posing (the latter lets a class present itself to the runtime as another class). It also includes methods that let you access runtime data structures, such as method selectors and function pointers to method implementations.
Interface Conventions
Some NSObject methods are meant only to be invoked while others are intended to be overridden. For example, most subclasses should not override allocWithZone: but they should implement init—or at least an initializer that ultimately invokes the root-class init method (see “Object Creation”). Of those methods that subclasses are expected to override, NSObject’s implementation either does nothing or returns some reasonable default value such as self. These default implementations make it possible to send basic messages such as init to any Cocoa object—even to an object whose class doesn’t override them—without risking a runtime exception. It’s not necessary to check (using respondsToSelector:) before sending the message. More importantly, the “placeholder” methods of NSObject define a common structure for Cocoa objects and establish conventions that, when followed by all classes, make object interactions more reliable.
Instance and Class Methods
The runtime system treats methods defined in the root class in a special way. Instance methods defined in a root class can be performed both by instances and by class objects. Therefore, all class objects have access to the instance methods defined in the root class. Any class object can perform any root instance method, provided it doesn’t have a class method with the same name.
For example, a class object could be sent messages to perform NSObject’s respondsToSelector: and performSelector:withObject: instance methods:
SEL method = @selector(riskAll:); |
if ([MyClass respondsToSelector:method]) |
[MyClass performSelector:method withObject:self]; |
Note that the only instance methods available to a class object are those defined in its root class. In the example above, if MyClass had re-implemented either respondsToSelector: or performSelector:withObject:, those new versions would be available only to instances. The class object for MyClass could perform only the versions defined in the NSObject class. (Of course, if MyClass had implemented respondsToSelector: or performSelector:withObject: as class methods rather than instance methods, the class would perform those new versions.)
Object Retention and Disposal
Beginning with Mac OS X version 10.5, Objective-C gives you two ways to ensure that objects persist when they are needed and are destroyed when they are no longer needed, thus freeing up memory. The preferred approach is to use the technology of garbage collection: the runtime detects objects that are no longer needed and disposes of them automatically. (It also happens to be the simpler approach in most cases.) The second approach, called memory management, is based on reference counting: an object carries with it a numerical value reflecting the current claims on the object; when this value reaches zero, the object is deallocated.
The amount of work that you, as a developer writing Objective-C code, must do to take advantage of garbage collection or memory management varies considerably.
Garbage Collection. To enable garbage collection, turn on the Enable Objective-C Garbage Collection build setting (the
-fobjc-gcflag). For each of your custom classes you might also have to implement thefinalizemethod to remove instances as a notification observers and to free any resources that are not instance variables. Also, ensure that in your nib files the object acting as File’s Owner maintains an outlet connection to each top-level nib object you want to persist.Memory Management. In memory-managed code each call that makes a claim of ownership on an object—object allocation and initialization, object copying, and
retain—must be balanced with a call that removes that claim—releaseandautorelease. When the object’s retain count (reflecting the number of claims on it) reaches zero, the object is deallocated and the memory occupied by the object is freed.
In addition to being easier to implement, garbage-collected code has several advantages over memory-managed code. Garbage collection provides a simple, consistent model for all participating programs while avoiding problems such as retain cycles. It also simplifies the implementation of accessor methods and makes it easier to ensure thread and exception safety.
Important: Although memory-management methods are “no-ops” in a garbage-collected application, there are still intractable differences between certain programming paradigms and patterns used in the two models. Therefore it is not recommended that you migrate a memory-managed application to a source base that tries to support both memory management and garbage collection. Instead, create a new full-version release that supports garbage collection.
The following sections explore how garbage collection and memory management work by following the life cycle of objects from their creation to their destruction.
Further Reading: To learn all about about the garbage-collection feature of Objective-C, read Garbage Collection Programming Guide. Memory management is discussed in detail in Memory Management Programming Guide for Cocoa.
How Garbage Collection Works
To the garbage collector, objects in a program are either reachable or are not reachable. Periodically the collector scans through the objects and collects those that are reachable. Those objects that aren’t reachable—the “garbage” objects—are finalized (that is, finalize is invoked). Subsequently, the memory they had occupied is freed.
The critical notion behind the architecture of the Objective-C garbage collector is the set of factors that constitute a reachable object. These start with an initial root set of objects: global variables (including NSApp), stack variables, and objects with external references (that is, outlets). The objects of the initial root set are never treated as garbage and therefore persist throughout the runtime life of the program. The collector adds to this initial set all objects that are directly reachable through strong references as well as all possible references found in the call stacks of every Cocoa thread. The garbage collector recursively follows strong references from the root set of objects to other objects, and from those objects to other objects, until all potentially reachable objects have been accounted for. (All references from one object to another object are considered strong references by default; weak references have to be explicitly marked as such.) In other words, a nonroot object persists at the end of a collection cycle only if the collector can reach it via strong references from a root object.
Figure 2-3 illustrates the general path the collector follows when it looks for reachable objects. But it also shows a few other important aspects of the garbage collector. The collector scans only a portion of a Cocoa program’s virtual memory for reachable objects. Scanned memory includes the call stacks of threads, global variables, and the auto zone, an area of memory from which all garbage collected blocks of memory are dispensed. The collector does not scan the malloc zone, which is the zone from which blocks of memory or allocated via the malloc function.
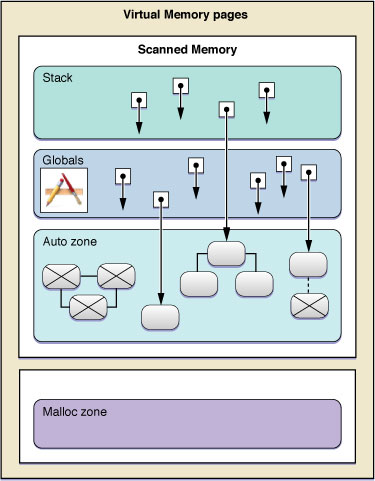
Another thing the diagram illustrates is that objects may have strong references to other objects, but if there is no chain of strong references that leads back to a root object, the object is considered unreachable and is disposed of at the end of a collection cycle. And indeed these references can be circular, but in garbage collection the circular references do not cause memory leaks, as do retain cycles in memory-managed code. All of these objects are disposed of when they are no longer reachable.
The Objective-C garbage collector is request-driven, not demand-driven. It initiates collection cycles only upon request, which Cocoa makes at intervals optimized for performance or when a certain memory threshold has been exceeded. You can also request collections using methods of the NSGarbageCollector class. The garbage collector is also generational. It makes not only exhaustive, or full, collections of program objects periodically, but it makes incremental collections based on the “generation” of objects. A object’s generation is determined by when it was allocated. Incremental collections, which are faster and more frequent than full collections, affect the more recently allocated objects. (Most objects are assumed to “die young”; if an object survives the first collection, it is likely to be intended to have a longer life.)
The garbage collector runs on one thread of a Cocoa program. During a collection cycle it will stop secondary threads to determine which objects in those threads are unreachable. But it never stops all threads at once, and it stops each thread for as short a time as possible. The collector is also conservative in that it never compacts auto-zone memory by relocating blocks of memory or updating pointers; once allocated, an object always stays in its original memory location.
How Memory Management Works
In memory-managed Objective-C code, a Cocoa object exists over a life span which, potentially at least, has distinct stages. It is created, initialized, and used (that is, other objects send messages to it). It is possibly retained, copied, or archived, and eventually it is released and destroyed. The following discussion charts the life of a typical object without going into much detail—yet.
Let’s begin at the end, at the way objects are disposed of when garbage collection is turned off. In this context Cocoa and Objective-C opt for a voluntary, policy-driven procedure for keeping objects around and disposing of them when they’re no longer needed.
This procedure and policy rest on the notion of reference counting. Each Cocoa object carries with it an integer indicating the number of other objects (or even procedural code sites) that are interested in its persistence. This integer is referred to as the object’s retain count (“retain” is used to avoid overloading the term “reference”). When you create an object, either by using a class factory method or by using the alloc or allocWithZone: class methods, Cocoa does a couple of very important things:
It sets the object’s
isapointer—theNSObjectclass's sole public instance variable—to point to the object’s class, thus integrating the object into the runtime’s view of the class hierarchy. (See “Object Creation” for further information.)It sets the object’s retain count—a kind of hidden instance variable managed by the runtime—to one. (The assumption here is that an object’s creator is interested in its persistence.)
After object allocation, you generally initialize an object by setting its instance variables to reasonable initial values. (NSObject declares the init method as the prototype for this purpose.) The object is now ready to be used; you can send messages to it, pass it to other objects, and so on.
Note: Because an initializer can return an object other than the one explicitly allocated, the convention is to nest the alloc message expression in the init message (or other initializer)—for example:
id anObj = [[MyClass alloc] init];When you release an object—that is, send a release message to it—NSObject decrements its retain count. If the retain count falls from one to zero, the object is deallocated. Deallocation takes place in two steps. First, the object’s dealloc method is invoked to release instance variables and free dynamically allocated memory. Then the operating system destroys the object itself and reclaims the memory the object once occupied.
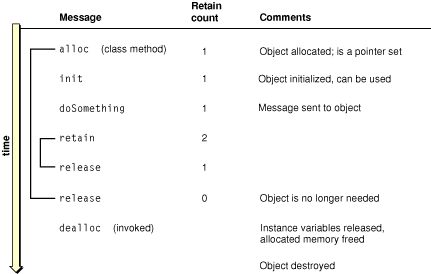
What if you don’t want an object to go away any time soon? If after receiving an object from somewhere you send it a retain message, the object’s retain count is incremented to two. Now two release messages are required before deallocation occurs. Figure 2-4 depicts this rather simplistic scenario.
Of course, in this scenario the creator of an object has no need to retain the object. It owns the object already. But if this creator were to pass the object to another object in a message, the situation changes. In an Objective-C program, an object received from some other object is always assumed to be valid within the scope it is obtained. The receiving object can send messages to the received object and can pass it to other objects. This assumption requires the sending object to “behave” and not prematurely free the object while a client object has a reference to it.
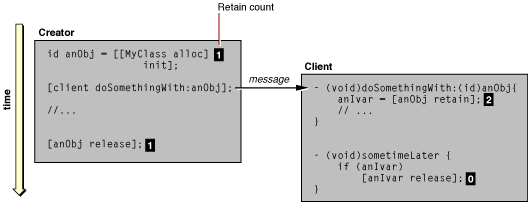
If the client object wants to keep the received object around after it goes out of programmatic scope, it can retain it—that is, send it a retain message. Retaining an object increments its retain count, thereby expressing an ownership interest in the object. The client object assumes a responsibility to release the object at some later time. If the creator of an object releases it, but a client object has retained that same object, the object persists until the client releases it. Figure 2-5 illustrates this sequence.
Instead of retaining an object you could copy it by sending it a copy or copyWithZone: message. (Many, if not most, subclasses encapsulating some kind of data adopt or conform to this protocol.) Copying an object not only duplicates it but almost always resets its retain count to one (see Figure 2-6). The copy can be shallow or deep, depending on the nature of the object and its intended usage. A deep copy duplicates the objects held as instance variables of the copied object while a shallow copy duplicates only the references to those instance variables.
In terms of usage, what differentiates a copy from a retain is that the former claims the object for the sole use of the new owner; the new owner can mutate the copied object without regard to its origin. Generally you copy an object instead of retaining it when it is a value object—that is, an object encapsulating some primitive value. This is especially true when that object is mutable, such as an NSMutableString. For immutable objects, copy and retain can be equivalent and might be implemented similarly.
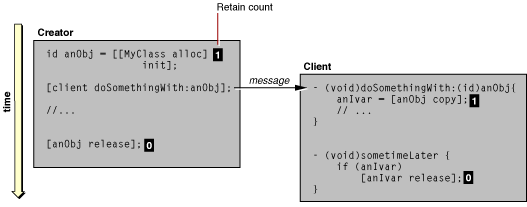
You might have noticed a potential problem with this scheme for managing the object life cycle. An object that creates an object and passes it to another object cannot always know when it can release the object safely. There could be multiple references to that object on the call stack, some by objects unknown to the creating object. If the creating object releases the created object and then some other object sends a message to that now-destroyed object, the program could crash. To get around this problem, Cocoa introduces a mechanism for deferred deallocation called autoreleasing.
Autoreleasing makes use of autorelease pools (defined by the NSAutoreleasePool class). A autorelease pool is a collection of objects within an explicitly defined scope that are marked for eventual release. Autorelease pools can be nested. When you send an object an autorelease message, a reference to that object is put into the most immediate autorelease pool. It is still a valid object, so other objects within the scope defined by the autorelease pool can send messages to it. When program execution reaches the end of the scope, the pool is released and, as a consequence, all objects in the pool are released as well (see Figure 2-7). If you are developing an application you may not need to set up an autorelease pool; the Application Kit automatically sets up an autorelease pool scoped to the application’s event cycle.
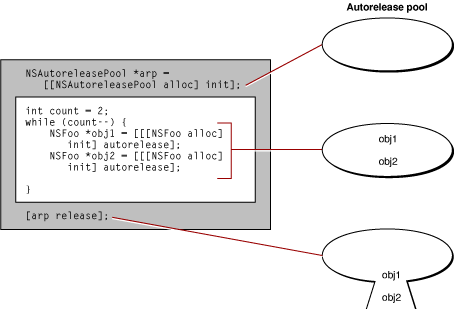
iPhone OS Note: Because on iPhone OS an application executes in a more memory-constrained environment, the use of autorelease pools is discouraged in methods or blocks of code (for example, loops) where an application creates many objects. Instead, you should explicitly release objects whenever possible.
So far the discussion of the object life cycle has focused on the mechanics of managing objects through that cycle. But a policy of object ownership guides the use of these mechanisms. This policy can be summarized as follows:
If you create an object by allocating and initializing it (for example,
[[MyClass alloc] init]), you own the object and are responsible for releasing it. This rule also applies if you use the NSObject convenience methodnew.If you copy an object, you own the copied object and are responsible for releasing it.
If you retain an object, you have partial ownership of the object and must release it when you no longer need it.
Conversely,
If you receive an object from some other object, you do not own the object and should not release it. (There are a handful of exceptions to this rule, which are explicitly noted in the reference documentation.)
As with any set of rules, there are exceptions and “gotchas”:
If you create an object using a class factory method (such as the
NSMutableArrayarrayWithCapacity:method), assume that the object you receive has been autoreleased. You should not release the object yourself and should retain it if you want to keep it around.To avoid cyclic references, a child object should never retain its parent. (A parent is the creator of the child or is an object holding the child as instance variable.)
Note: “Release” in the above guidelines means sending either a release message or an autorelease message to an object.
If you do not follow this ownership policy, two bad things are likely to happen in your Cocoa program. Because you did not release created, copied, or retained objects, your program is now leaking memory. Or your program crashes because you sent a message to an object that was deallocated out from under you. And here’s a further caveat: debugging these problems can be a time-consuming affair.
A further basic event that could happen to an object during its life cycle is archiving. Archiving converts the web of interrelated objects that comprise an object-oriented program—the object graph—into a persistent form (usually a file) that preserves the identity and relationships of each object in the graph. When the program is unarchived, its object graph is reconstructed from this archive. To participate in archiving (and unarchiving), an object must be able to encode (and decode) its instance variables using the methods of the NSCoder class. NSObject adopts the NSCoding protocol for this purpose. For more information on the archiving of objects, see “Object Archives”.
Object Creation
The creation of a Cocoa object always takes place in two stages: allocation and initialization. Without both steps an object generally isn’t usable. Although in almost all cases initialization immediately follows allocation, the two operations play distinct roles in the formation of an object.
Allocating an Object
When you allocate an object, part of what happens is what you might expect, given the term “allocate.” Cocoa allocates enough memory for the object from a region of application virtual memory. To calculate how much memory to allocate, it takes the object’s instance variables into account—including their types and order—as specified by the object’s class.
To allocate an object, you send the message alloc or allocWithZone: to the object’s class. In return, you get a “raw” (uninitialized) instance of the class. The alloc variant of the method uses the application’s default zone. A zone is a page-aligned area of memory for holding related objects and data allocated by an application. See Memory Management Programming Guide for Cocoa for more information on zones.
An allocation message does other important things besides allocating memory:
It sets the object’s retain count to one (as described in “How Memory Management Works”).
It initializes the object’s
isainstance variable to point to the object’s class, a runtime object in its own right that is compiled from the class definition.It initializes all other instance variables to zero (or to the equivalent type for zero, such as
nil,NULL, and0.0).
An object’s isa instance variable is inherited from NSObject, so it is common to all Cocoa objects. After allocation sets isa to the object’s class, the object is integrated into the runtime’s view of the inheritance hierarchy and the current network of objects (class and instance) that constitute a program. Consequently an object can find whatever information it needs at runtime, such as another object’s place in the inheritance hierarchy, the protocols that other objects conform to, and the location of the method implementations it can perform in response to messages.
In summary, allocation not only allocates memory for an object but initializes two small but very important attributes of any object: its isa instance variable and its retain count. It also sets all remaining instance variables to zero. But the resulting object is not yet usable. Initializing methods such as init must yet initialize objects with their particular characteristics and return a functional object.
Initializing an Object
Initialization sets the instance variables of an object to reasonable and useful initial values. It can also allocate and prepare other global resources needed by the object, loading them if necessary from an external source such as a file. Every object that declares instance variables should implement an initializing method—unless the default set-everything-to-zero initialization is sufficient. If an object does not implement an initializer, Cocoa invokes the initializer of the nearest ancestor instead.
The Form of Initializers
NSObject declares the init prototype for initializers; it is an instance method typed to return an object of type id. Overriding init is fine for subclasses that require no additional data to initialize their objects. But often initialization depends on external data to set an object to a reasonable initial state. For example, say you have an Account class; to initialize an Account object appropriately requires a unique account number, and this must be supplied to the initializer. Thus initializers can take one or more arguments; the only requirement is that the initializing method begins with the letters “init”. (The stylistic convention init... is sometimes used to refer to initializers.)
Note: Instead of implementing an initializer with arguments, a subclass may implement only a simple init method and then use “set” accessor methods immediately after initialization to set the object to a useful initial state. (Accessor methods enforce encapsulation of object data by setting and getting the values of instance variables.) Or, if the subclass uses properties and the related access syntax, it may assign values to the properties immediately after initialization.
Cocoa has plenty of examples of initializers with arguments. Here are a few (with the defining class in parentheses):
- (id)initWithArray:(NSArray *)array;(fromNSSet)- (id)initWithTimeInterval:(NSTimeInterval)secsToBeAdded sinceDate:(NSDate *)anotherDate;(fromNSDate)- (id)initWithContentRect:(NSRect)contentRect styleMask:(unsigned int)aStyle backing:(NSBackingStoreType)bufferingType defer:(BOOL)flag;(fromNSWindow)- (id)initWithFrame:(NSRect)frameRect;(fromNSControlandNSView)
These initializers are instance methods that begin with “init” and return an object of the dynamic type id. Other than that, they follow the Cocoa conventions for multi-argument methods, often using WithType: or FromSource: before the first and most important argument.
Issues with Initializers
Although init... methods are required by their method signature to return an object, that object is not necessarily the one that was most recently allocated—the receiver of the init... message. In other words, the object you get back from an initializer might not be the one you thought was being initialized.
Two conditions prompt the return of something other than the just-allocated object. The first involves two related situations: when there must be a singleton instance or when the defining attribute of an object must be unique. Some Cocoa classes—NSWorkspace, for instance—allow only one instance in a program; a class in such a case must ensure (in an initializer or, more likely, in a class factory method) that only one instance is created, returning this instance if there is any further request for a new one. (See “Creating a Singleton Instance” for information on implementing a singleton object.)
A similar situation arises when an object is required to have an attribute that makes it unique. Recall the hypothetical Account class mentioned earlier. An account of any sort must have a unique identifier. If the initializer for this class—say, initWithAccountID:—is passed an identifier that has already been associated with an object, it must do two things:
Release the newly allocated object (in memory-managed code).
Return the Account object previously initialized with this unique identifier.
By doing this, the initializer ensures the uniqueness of the identifier while providing what was asked for: an Account instance with the requested identifier.
Sometimes an init... method cannot perform the initialization requested. For example, an initFromFile: method expects to initialize an object from the contents of a file, the path to which is passed an argument. But if no file exists at that location the object cannot be initialized. A similar problem would happen if an initWithArray: initializer was passed an NSDictionary object instead of an NSArray object. When an init... method cannot initialize an object, it should:
Release the newly allocated object (in memory-managed code).
Return
nil.
Returning nil from an initializer indicates that the requested object cannot be created. When you create an object, you should generally check whether the returned value is nil before proceeding:
id anObject = [[MyClass alloc] init]; |
if (anObject) { |
[anObject doSomething]; |
// more messages... |
} else { |
// handle error |
} |
Because an init... method might return nil or an object other than the one explicitly allocated, it is dangerous to use the instance returned by alloc or allocWithZone: instead of the one returned by the initializer. Consider the following code:
id myObject = [MyClass alloc]; |
[myObject init]; |
[myObject doSomething]; |
The init method in this example could have returned nil or could have substituted a different object. Because you can send a message to nil without raising an exception, nothing would happen in the former case except (perhaps) a debugging headache. But you should always rely on the initialized instance instead of the “raw” just-allocated one. It is recommended that you nest the allocation and initialization messages and test the object returned from the initializer before proceeding.
id myObject = [[MyClass alloc] init]; |
if ( myObject ) { |
[myObject doSomething]; |
} else { |
// error recovery... |
} |
Once an object is initialized, you should not initialize it again. If you attempt a re-initialization, the framework class of the instantiated object often raises an exception. For example, the second initialization in this example would result in an NSInvalidArgumentException being raised.
NSString *aStr = [[NSString alloc] initWithString:@"Foo"]; |
aStr = [aStr initWithString:@"Bar"]; |
Implementing an Initializer
There are several critical steps to follow when implementing an init... method that serves as a class’s sole initializer or, if there are multiple initializers, its designated initializer (described in “Multiple Initializers and the Designated Initializer”):
Always invoke the superclass (
super) initializer first.Check the object returned by the superclass. If it is
nil, then initialization cannot proceed; returnnilto the receiver.When initializing instance variables that are references to objects, retain or copy the object as necessary (in memory-managed code).
After setting instance variables to valid initial values, return
selfunless:It was necessary to return a substituted object, in which case release the freshly allocated object first (in memory-managed code).
A problem prevented initialization from succeeding, in which case return
nil.
The init... method in Listing 2-3 illustrates these steps:
Listing 2-3 An example of an initializer
- (id)initWithAccountID:(NSString *)identifier { |
if ( self = [super init] ) { |
Account *ac = [accountDictionary objectForKey:identifier]; |
if (ac) { // object with that ID already exists |
[self release]; |
return [ac retain]; |
} |
if (identifier) { |
accountID = [identifier copy]; // accountID is instance variable |
[accountDictionary setObject:self forKey:identifier]; |
return self; |
} else { |
[self release]; |
return nil; |
} |
} else |
return nil; |
} |
Note: Although, for the sake of simplicity, this example returns nil if the argument is nil, the better Cocoa practice is to raise an exception.
It isn’t necessary to initialize all instance variables of an object explicitly, just those that are necessary to make the object functional. The default set-to-zero initialization performed on an instance variable during allocation is often sufficient. Make sure that you retain or copy instance variables, as required for memory management.
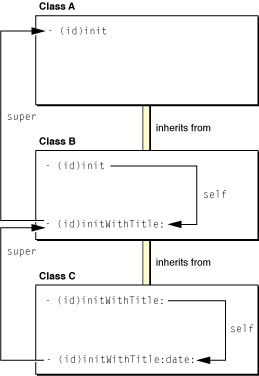
The requirement to invoke the superclass’ initializer as the first thing is important. Recall that an object encapsulates not only the instance variables defined by its class but the instance variables defined by all of its ancestor classes. By invoking super’s initializer first you help to ensure that the instance variables defined by classes up the inheritance chain are initialized first. The immediate superclass, in its initializer, invokes the initializer of its superclass, which invokes its superclasses main init... method, and so on (see Figure 2-8). The proper order of initialization is critical because the later initializations of subclasses may depend on superclass-defined instance variables being initialized to reasonable values.
Inherited initializers are a concern when you create a subclass. Sometimes a superclass init... method sufficiently initializes instances of your class. But it is more likely it won’t, and so you should override it. If you don’t, the superclass implementation will be invoked, and since the superclass knows nothing about your class, your instances may not be correctly initialized.
Multiple Initializers and the Designated Initializer
A class can define more than one initializer. Sometimes multiple initializers let clients of the class provide the input for the same initialization in different forms. The NSSet class, for example, offers clients several initializers that accept the same data in different forms; one takes an NSArray object, another a counted list of elements, and another a nil-terminated list of elements:
- (id)initWithArray:(NSArray *)array; |
- (id)initWithObjects:(id *)objects count:(unsigned)count; |
- (id)initWithObjects:(id)firstObj, ...; |
Some subclasses provide convenience initializers that supply default values to an initializer that takes the full complement of initialization parameters. This initializer is usually the designated initializer, the most important initializer of a class. For example, assume there is a Task class and it declares a designated initializer with this signature:
- (id)initWithTitle:(NSString *)aTitle date:(NSDate *)aDate; |
The Task class might include secondary, or convenience, initializers that simply invoke the designated initializer, passing it default values for those parameters the secondary initializer doesn’t explicitly request (Listing 2-4).
Listing 2-4 Secondary initializers
- (id)initWithTitle:(NSString *)aTitle { |
return [self initWithTitle:aTitle date:[NSDate date]]; |
} |
- (id)init { |
return [self initWithTitle:@"Task"]; |
} |
The designated initializer plays an important role for a class. It ensures that inherited instance variables are initialized by invoking super’s designated initializer. It is typically the init... method that has the most arguments and that does most of the initialization work, and it is the initializer that secondary initializers of the class invoke with messages to self.
When you define a subclass you must be able to identify the designated initializer of the superclass and invoke it in your subclass’s designated initializer through a message to super. You must also make sure that inherited initializers are covered in some way. And you may provide as many convenience initializers as you deem necessary. When designing the initializers of your class, keep in mind that designated initializers are chained to each other through messages to super while other initializers are chained to the designated initializer of their class through messages to self.
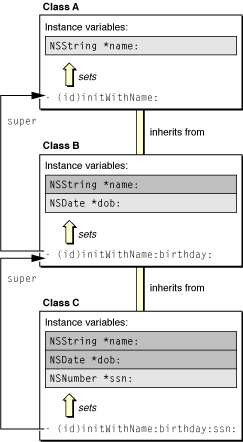
An example will make this clearer. Let’s say there are three classes, A, B, and C; class B inherits from class A, and class C inherits from class B. Each subclass adds an attribute as an instance variable and implements an init... method—the designated initializer—to initialize this instance variable. They also define secondary initializers and ensure that inherited initializers are overridden, if necessary. Figure 2-9 illustrates the initializers of all three classes and their relationships.
The designated initializer for each class is the initializer with the most coverage; it is the method that initializes the attribute added by the subclass. The designated initializer is also the init... method that invokes the designated initializer of the superclass in a message to super. In this example, the designated initializer of class C, initWithTitle:date:, invokes the designated initializer of its superclass, initWithTitle:, which in turn invokes the init method of class A. When creating a subclass, it’s always important to know the designated initializer of the superclass.
While designated initializers are thus connected up the inheritance chain through messages to super, secondary initializers are connected to their class’s designated initializer through messages to self. Secondary initializers (as in this example) are frequently overridden versions of inherited initializers. Class C overrides initWithTitle: to invoke its designated initializer, passing it a default date. This designated initializer, in turn, invokes the designated initializer of class B, which is the overridden method, initWithTitle:. If you sent an initWithTitle: message to objects of class B and class C, you’d be invoking different method implementations. On the other hand, if class C did not override initWithTitle: and you sent the message to an instance of class C, the class B implementation would be invoked. Consequently, the C instance would be incompletely initialized (since it would lack a date). When creating a subclass, it’s important to make sure that all inherited initializers are adequately covered.
Sometimes the designated initializer of a superclass may be sufficient for the subclass, and so there is no need for the subclass to implement its own designated initializer. Other times, a class’s designated initializer may be an overridden version of its superclasses designated initializer. This is frequently the case when the subclass needs to supplement the work performed by the superclass’s designated initializer, even though the subclass does not add any instance variables of its own (or the instance variables it does add don’t require explicit initialization).
The dealloc and finalize Methods
In Cocoa classes that use garbage collection, the finalize method is the place where the class disposes of any remaining resources and attachments of its instances before those instances are freed. In Cocoa classes that use traditional memory management, the comparable method for resource cleanup is the dealloc method. Although similar in purpose, there are significant differences in how these methods should be implemented.
In many respects, the dealloc method is the counterpart to a class’s init... method, especially its designated initializer. Instead of being invoked just after the allocation of an object, dealloc is invoked just prior to the object’s destruction. Instead of ensuring that the instance variables of an object are properly initialized, the dealloc method makes sure that object instance variables are released and that any dynamically allocated memory has been freed.
The final point of parallelism has to do with the invocation of the superclass implementation of the same method. In an initializer, you invoke the superclasses designated initializer as the first step. In dealloc, you invoke the superclasses dealloc implementation as the last step. The reason for this is mirror-opposite to that for initializers; subclasses should release or free the instance variables they own first before the instance variables of ancestor classes are released or freed.
Listing 2-5 shows how you might implement this method.
Listing 2-5 An example dealloc method
- (void)dealloc { |
[accountDictionary release]; |
free(mallocdChunk); |
[super dealloc]; |
} |
Note that this example does not verify that accountDictionary (an instance variable) is non-nil before releasing it. That is because Objective-C lets you safely send a message to nil.
Similar to the dealloc method, the finalize method is the place to close resources used by an object in a garbage-collected environment prior to that object being freed and its memory reclaimed. As in dealloc, the final line of a finalize implementation should invoke the superclass implementation of the method. However, unlike dealloc, a finalize implementation does not have to release instance variables because the garbage collector destroys these objects at the proper time.
But there is a more significant difference between these “cleanup” methods. It is actually recommended that you do not implement a finalize method if possible. And, if you must implement finalize, you should reference as few other objects as possible. The primary reason for this admonition is that the order in which garbage-collected objects are sent finalize is indeterminate, even if there are references between them. Thus the consequences are indeterminate, and potentially negative, if messages pass between objects being finalized. Your code cannot depend on the side effects arising from the order of deallocation, as it can in dealloc. Generally, you should try to architect your code so that such actions as freeing malloc’d blocks, closing file descriptors, and unregistering observers happen before finalize is invoked.
Further Reading: To learn about approaches to implementing the finalize method, read “Implementing a finalize Method" in Garbage Collection Programming Guide.
Class Factory Methods
Class factory methods are implemented by a class as a convenience for clients. They combine allocation and initialization in one step and return the created object autoreleased (in memory-managed code). These methods are of the form + (type)className... (where className excludes any prefix).
Cocoa provides plenty of examples, especially among the “value” classes. NSDate includes the following class factory methods:
+ (id)dateWithTimeIntervalSinceNow:(NSTimeInterval)secs; |
+ (id)dateWithTimeIntervalSinceReferenceDate:(NSTimeInterval)secs; |
+ (id)dateWithTimeIntervalSince1970:(NSTimeInterval)secs; |
And NSData offers the following factory methods:
+ (id)dataWithBytes:(const void *)bytes length:(unsigned)length; |
+ (id)dataWithBytesNoCopy:(void *)bytes length:(unsigned)length; |
+ (id)dataWithBytesNoCopy:(void *)bytes length:(unsigned)length |
freeWhenDone:(BOOL)b; |
+ (id)dataWithContentsOfFile:(NSString *)path; |
+ (id)dataWithContentsOfURL:(NSURL *)url; |
+ (id)dataWithContentsOfMappedFile:(NSString *)path; |
Factory methods can be more than a simple convenience. They can not only combine allocation and initialization, but the allocation can inform the initialization. As an example, let’s say you must initialize a collection object from a property-list file that encodes any number of elements for the collection (NSString objects, NSData objects, NSNumber objects, and so on). Before the factory method can know how much memory to allocate for the collection, it must read the file and parse the property list to determine how many elements there are and what object type these elements are.
Another purpose for a class factory method is to ensure that a certain class (NSWorkspace, for example) vends a singleton instance. Although an init... method could verify that only one instance exists at any one time in a program, it would require the prior allocation of a “raw” instance and then, in memory-managed code, would have to release that instance. A factory method, on the other hand, gives you a way to avoid blindly allocating memory for an object that you might not use (see Listing 2-6).
Listing 2-6 A factory method for a singleton instance
static AccountManager *DefaultManager = nil; |
+ (AccountManager *)defaultManager { |
if (!DefaultManager) DefaultManager = [[self allocWithZone:NULL] init]; |
return DefaultManager; |
} |
Further Reading: For a more detailed discussion of issues relating to the allocation and initialization of Cocoa objects, see “The Runtime System“ in The Objective-C 2.0 Programming Language.
Introspection
Introspection is a powerful feature of object-oriented languages and environments, and Objective-C and Cocoa are particularly generous with this feature. Introspection refers to the capability of objects to divulge details about themselves as objects at runtime. Such details include an object’s place in the inheritance tree, whether it conforms to a specific protocol, and whether it responds to a certain message. The NSObject protocol and class define many introspection methods that you can use to query the runtime in order to characterize objects.
Used judiciously, introspection makes an object-oriented program more efficient and robust. It can help you to avoid message-dispatch errors, erroneous assumptions of object equality, and similar problems. The following sections show how you might effectively use the NSObject introspection methods in your code.
Evaluating Inheritance Relationships
Once you know the class an object belongs to, you probably know quite a bit about the object. You might know what its capabilities are, what attributes it represents, and what kinds of messages it can respond to. Even if after introspection you are unfamiliar with the class to which an object belongs, you now know enough to not send it certain messages.
The NSObject protocol declares several methods for determining an object’s position in the class hierarchy. These methods operate at different granularities. The class and superclass instance methods, for example, return the Class objects representing the class and superclass, respectively, of the receiver. These methods require you to compare one Class object with another. Listing 2-7 gives a simple (one might say trivial) example of their use.
Listing 2-7 Using the class and superclass methods
// ... |
while ( id anObject = [objectEnumerator nextObject] ) { |
if ( [self class] == [anObject superclass] ) { |
// do something appropriate... |
} |
} |
Note: Sometimes you use the class or superclass methods to obtain an appropriate receiver for a class message.
More commonly to check an object’s class affiliation, you would send it a isKindOfClass: or isMemberOfClass: message. The former method returns whether the receiver is an instance of a given class or an instance of any class that inherits from that class. A isMemberOfClass: message, on the other hand, tells you if the receiver is an instance of the specified class. The isKindOfClass: method is generally more useful because from it you can know at once the complete range of messages you can send to an object. Consider the code snippet in Listing 2-8.
Listing 2-8 Using isKindOfClass:
if ([item isKindOfClass:[NSData class]]) { |
const unsigned char *bytes = [item bytes]; |
unsigned int length = [item length]; |
// ... |
} |
By learning that the object item inherits from the NSData class, this code knows it can send it the NSData bytes and length messages. The difference between isKindOfClass: and isMemberOfClass: becomes apparent if you assume that item is an instance of NSMutableData. If you use isMemberOfClass: instead of isKindOfClass:, the code in the conditionalized block is never executed because item is not an instance of NSData but rather of NSMutableData, a subclass of NSData.
Method Implementation and Protocol Conformance
Two of the more powerful introspection methods of NSObject are respondsToSelector: and conformsToProtocol:. These methods tell you, respectively, whether an object implements a certain method and whether an object conforms to a specified formal protocol (that is, adopts the protocol, if necessary, and implements all the methods of the protocol).
You use these methods in a similar situation in your code. They enable you to discover whether some potentially anonymous object will respond appropriately to a particular message or set of messages before you send it any of those messages. By making this check before sending a message, you can avoid the risk of runtime exceptions resulting from unrecognized selectors. The Application Kit implements informal protocols—the basis of delegation—by checking whether delegates implement a delegation method (using respondsToSelector:) prior to invoking that method.
Listing 2-9 illustrates how you might use the respondsToSelector: method in your code:
Listing 2-9 Using respondsToSelector:
- (void)doCommandBySelector:(SEL)aSelector { |
if ([self respondsToSelector:aSelector]) { |
[self performSelector:aSelector withObject:nil]; |
} else { |
[_client doCommandBySelector:aSelector]; |
} |
} |
Listing 2-10 illustrates how you might use the conformsToProtocol: method in your code:
Listing 2-10 Using conformsToProtocol:
// ... |
if (!([((id)testObject) conformsToProtocol:@protocol(NSMenuItem)])) { |
NSLog(@"Custom MenuItem, '%@', not loaded; it must conform to the |
'NSMenuItem' protocol.\n", [testObject class]); |
[testObject release]; |
testObject = nil; |
} |
Object Comparison
Although they are not strictly introspection methods, the hash and isEqual: methods fulfill a similar role. They are indispensable runtime tools for identifying and comparing objects. But instead of querying the runtime for information about an object, they rely on class-specific comparison logic.
The hash and isEqual: methods, both declared by the NSObject protocol, are closely related. The hash method must be implemented to return an integer that can be used as a table address in a hash table structure. If two objects are equal (as determined by the isEqual: method), they must have the same hash value. If your object could be included in collections such as NSSet, you need to define hash and verify the invariant that if two objects are equal, they return the same hash value. The default NSObject implementation of isEqual: simply checks for pointer equality.
Using the isEqual: method is straightforward; it compares the receiver against the object supplied as argument. Object comparison frequently informs runtime decisions about what should be done with an object. As Listing 2-11 illustrates, you can use isEqual: to decide whether to perform an action, in this case to save user preferences that have been modified.
Listing 2-11 Using isEqual:
- (void)saveDefaults { |
NSDictionary *prefs = [self preferences]; |
if (![origValues isEqual:prefs]) |
[Preferences savePreferencesToDefaults:prefs]; |
} |
If you are creating a subclass, you might need to override isEqual: to add further checks for points of equality. The subclass might define an extra attribute that might have to be the same value in two instances for them to be considered equal. For example, say you create a subclass of NSObject called MyWidget that contains two instance variables, name and data. Both of these must be the same value for two instances of MyWidget to be considered equal. Listing 2-12 illustrates how you might implement isEqual: for the MyWidget class.
Listing 2-12 Overriding isEqual:
- (BOOL)isEqual:(id)other { |
if (other == self) |
return YES; |
if (!other || ![other isKindOfClass:[self class]]) |
return NO; |
return [self isEqualToWidget:other]; |
} |
- (BOOL)isEqualToWidget:(MyWidget *)aWidget { |
if (self == aWidget) |
return YES; |
if (![(id)[self name] isEqual:[aWidget name]]) |
return NO; |
if (![[self data] isEqualToData:[aWidget data]]) |
return NO; |
return YES; |
} |
This isEqual: method first checks for pointer equality, then class equality, and finally invokes an object comparator whose name indicates the class of object involved in the comparison. This type of comparator, which forces type-checking of the object passed in, is a common convention in Cocoa; the NSString isEqualToString: and the NSTimeZone isEqualToTimeZone: are but two examples. The class-specific comparator—isEqualToWidget: in this case—performs the checks for name and data equality.
In all isEqualToType: methods of the Cocoa frameworks nil is not a valid argument and implementations of these methods may raise an exception upon receiving a nil. However, for backwards compatibility, isEqual: methods of the Cocoa frameworks do accept nil, returning NO.
Object Mutability
Cocoa objects are either mutable or immutable. You cannot change the encapsulated values of immutable objects; once such an object is created, the value it represents remains the same throughout the object’s life. But you can change the encapsulated value of a mutable object at any time. The following sections explain the reasons for having mutable and immutable variants of an object type, describes the characteristics and side-effects of object mutability, and recommends how best to handle objects when their mutability is an issue.
Why Mutable and Immutable Object Variants?
Objects by default are mutable. Most objects allow you to change their encapsulated data through “setter” accessor methods. For example, you can change the size, positioning, title, buffering behavior, and other characteristics of an NSWindow object. A well-designed model object—say, an object representing a customer record—requires setter methods to change its instance data.
The Foundation framework adds some nuance to this picture by introducing classes that have mutable and immutable variants. The mutable subclasses are typically subclasses of their immutable superclass and have “Mutable” embedded in the class name. These classes include the following:
Note: Except for NSMutableParagraphStyle in the Application Kit, the Foundation framework currently defines all explicitly named mutable classes. However, any Cocoa framework can potentially have its own mutable and immutable class variants.
Although these classes have atypical names, they are closer to the mutable norm than their immutable counterparts. Why this complexity? What purpose does having an immutable variant of a mutable object serve?
Consider a scenario where all objects are capable of being mutated. In your application you invoke a method and are handed back a reference to an object representing a string. You use this string in your user interface to identify a particular piece of data. Now another subsystem in your application gets its own reference to that same string and decides to mutate it. Suddenly your label has changed out from under you. Things can become even more dire if, for instance, you get a reference to an array that you use to populate a table view. The user selects a row corresponding to an object in the array that has been removed by some code elsewhere in the program—problems ensue. Immutability is a guarantee that an object won’t unexpectedly change in value while you’re using it.
Objects that are good candidates for immutability are ones that encapsulate collections of discrete values or contain values that are stored in buffers (which are themselves kinds of collections, either of characters or bytes). But not all “value” objects necessarily benefit from having mutable versions. Objects that contain a single simple value, such as instances of NSNumber or NSDate, are not good candidates for mutability. When the represented value changes in these cases, it makes more sense to replace the old instance with a new instance.
Performance is also a reason for immutable versions of objects representing things such as strings and dictionaries. Mutable objects such as these bring some overhead with them. Because they must dynamically manage a changeable backing store—allocating and deallocating chunks of memory as needed—mutable objects can be less efficient than their immutable counterparts.
Although in theory immutability guarantees that an object’s value is stable, in practice this guarantee isn’t always assured. A method may choose to hand out a mutable object under the return type of its immutable variant; later, it may decide to mutate the object, possibly violating assumptions and choices the recipient has made based on the earlier value. The mutability of an object itself may change as it undergoes various transformations. For example, serializing a property list (using the NSPropertyListSerialization class) does not preserve the mutability aspect of objects, only their general kind—a dictionary, an array, and so on. Thus, when you deserialize this property list, the resulting objects might not be of the same class as the original objects. For instance, what was once an NSMutableDictionary object might now be a NSDictionary object.
Programming With Mutable Objects
When the mutability of objects is an issue, it’s best to adopt some defensive programming practices. Here are a few general rules of thumb:
Use a mutable variant of an object when you need to modify its contents frequently and incrementally after it has been created.
Sometimes it’s preferable to replace one immutable object with another; for example, most instance variables that hold string values should be assigned immutable NSString objects that are replaced with “setter” methods.
Rely on the return type for indications of mutability.
if you have any doubts about whether an object is, or should be, mutable, go with immutable.
This section explores the gray areas in these rules of thumb, discussing typical choices you have to make when programming with mutable objects. It also gives an overview of methods in the Foundation framework for creating mutable objects and for converting between mutable and immutable object variants.
Creating and Converting Mutable Objects
You can create a mutable object through the standard nested alloc-init message, for example:
NSMutableDictionary *mutDict = [[NSMutableDictionary alloc] init]; |
However, many mutable classes offer initializers and factory methods that let you specify the initial or probable capacity of the object, such as the arrayWithCapacity: class method of NSMutableArray:
NSMutableArray *mutArray = [NSMutableArray arrayWithCapacity:[timeZones count]]; |
This hint enables more efficient storage of the mutable object’s data. (Because the convention for class factory methods is to return autoreleased instances, be sure to retain the object if you wish to keep it viable in your code.)
You can also create a mutable object by making a mutable copy of an existing object of that general type. To do so, invoke the mutableCopy method that each immutable super class of a Foundation mutable class implements:
NSMutableSet *mutSet = [aSet mutableCopy]; |
In the other direction, you can send copy to a mutable object to make an immutable copy of it.
Many Foundation classes with immutable and mutable variants include methods for converting between the variants, including:
type
WithType:—for example,arrayWithArray:setType:—for example,setString:(mutable classes only)initWithType:copyItems:—for example,initWithDictionary:copyItems:
Storing and Returning Mutable Instance Variables
A common decision in Cocoa development is whether to make an instance variable mutable or immutable. For an instance variable whose value can change, such as a dictionary or string, when is it appropriate to make the object mutable? And when is it better to make the object immutable and replace it with another object when its represented value changes?
Generally, when you have an object whose contents change wholesale, it’s better to use an immutable object. Strings (NSString) and data objects (NSData) usually fall into this category. If an object is likely to change incrementally, it is a reasonable approach to make it mutable. Collections such as arrays and dictionaries fall into this category. However, the frequency of changes and the size of the collection should be factors in this decision. For example, if you have a small array that seldom changes, it’s better to make it immutable.
There are a couple of other considerations when deciding on the mutability of an collection held as an instance variable:
If you have a mutable collection that is frequently changed and that you frequently hand out to clients (that is, you return it directly in a “getter” accessor method) you run the risk of mutating something that your clients might have a reference to. If this risk is probable, the instance variable should be immutable.
If the value of the instance variable frequently changes but you rarely return it to clients in getter methods, you can make the instance variable mutable but return an immutable copy of it in your accessor method; in memory-managed programs, this object would be autoreleased (Listing 2-13).
Listing 2-13 Returning an immutable copy of a mutable instance variable
@interface MyClass : NSObject { |
// ... |
NSMutableSet *widgets; |
} |
// ... |
@end |
@implementation MyClass |
- (NSSet *)widgets { |
return (NSSet *)[[widgets copy] autorelease]; |
} |
One sophisticated approach for handling mutable collections that are returned to clients is to maintain a flag that records whether the object is currently mutable or immutable. If there is a change, make the object mutable and apply the change. When handing out the collection, make the object immutable (if necessary) before returning it.
Receiving Mutable Objects
The invoker of a method is interested in the mutability of a returned object for two reasons:
It wants to know if it can change the object’s value.
It wants to know if the object’s value will change unexpectedly while it has a reference to it.
Use Return Type, Not Introspection
To determine whether it can change a received object, the receiver must rely on the formal type of the return value. If it receives, for instance, an array object typed as immutable, it should not attempt to mutate it. It is not an acceptable programming practice to determine if an object is mutable based on its class membership, for example:
if ( [anArray isKindOfClass:[NSMutableArray class]] ) { |
// add, remove objects from anArray |
} |
Because of implementation reasons, what isKindOfClass: returns in this case may not be accurate. But for reasons other than this, you should not make decisions on whether an object is mutable based on class membership. That decision should be guided solely by what the signature of the method vending the object says about its mutability. If you are not sure whether an object is mutable or immutable, assume it’s immutable.
A couple of examples might help clarify why this guideline is important:
You read a property list from a file. When the Foundation framework processes the list it notices that various subsets of the property list are identical, so it creates a set of objects that it shares among all those subsets. Afterwards you look at the created property list objects and decide to mutate one subset. Suddenly, and without being aware of it, you’ve changed the tree in multiple places.
You ask
NSViewfor its subviews (subviewsmethod) and it returns an object that is declared to be anNSArraybut which could be anNSMutableArrayinternally. Then you pass that array to some other code that, through introspection, determines it to be mutable and changes it. By changing this array, the code is mutatingNSView’s internal data structures.
So don’t make a decision on object mutability based on what introspection tells you about an object. Treat objects as mutable or not based on what you are handed at the API boundaries (that is, based on the return type). If you need to unambiguously mark an object as mutable or immutable when you pass it to clients, pass that information as a flag along with the object.
Make Snapshots of Received Objects
If you want to ensure that a supposedly immutable object received from a method does not mutate without your knowing about it, you can make “snapshots” of the object by copying it locally. Then occasionally compare the stored version of the object with the most recent version. If the object has mutated, you can adjust anything in your program that is dependent on the previous version of the object. Listing 2-14 shows a possible implementation of this technique.
Listing 2-14 Making a snapshot of a potentially mutable object
static NSArray *snapshot = nil; |
- (void)myFunction { |
NSArray *thingArray = [otherObj things]; |
if (snapshot) { |
if ( ![thingArray isEqualToArray:snapshot] ) { |
[self updateStateWith:thingArray]; |
} |
} |
snapshot = [thingArray copy]; |
} |
A problem with making snapshots of objects for later comparison is that it is expensive. You’re required to make multiple copies of the same object. A more efficient alternative is to use key-value observing. See “Key-Value Observing” for an overview of this protocol.
Mutable Objects in Collections
Storing mutable objects in collection objects can cause problems. Certain collections can become invalid or even corrupt if objects they contain mutate because, by mutating, these objects can affect the way they are placed in the collection. In the first case, the properties of objects that are keys in hashing collections such as NSDictionary objects or NSSet objects will, if changed, corrupt the collection if the changed properties affect the results of the object’s hash or isEqual: methods. (If the hash method of the objects in the collection does not depend on their internal state, corruption is less of a likelihood.) Second, if an object in an ordered collection such as a sorted array has its properties changed, this might affect how the object compares to other objects in the array, thus rendering the ordering invalid.
Class Clusters
Class clusters are a design pattern that the Foundation framework makes extensive use of. Class clusters group a number of private, concrete subclasses under a public, abstract superclass. The grouping of classes in this way simplifies the publicly visible architecture of an object-oriented framework without reducing its functional richness. Class clusters are based on the Abstract Factory design pattern discussed in “Cocoa Design Patterns.”
Simple Concept, Complex Interface
To illustrate the class cluster architecture and its benefits, consider the problem of constructing a class hierarchy that defines objects to store numbers of different types (char, int, float, double). Since numbers of different types have many features in common (they can be converted from one type to another and can be represented as strings, for example), they could be represented by a single class. However, their storage requirements differ, so it’s inefficient to represent them all by the same class. This suggests the following architecture:
Number is the abstract superclass that declares in its methods the operations common to its subclasses. However, it doesn’t declare an instance variable to store a number. The subclasses declare such instance variables and share in the programmatic interface declared by Number.
So far, this design is relatively simple. However, if the commonly used modifications of these basic C types are taken into account, the diagram looks more like this:

The simple concept—creating a class to hold number values—can easily burgeon to over a dozen classes. The class cluster architecture presents a design that reflects the simplicity of the concept.
Simple Concept, Simple Interface
Applying the class cluster design pattern to this problem yields the following hierarchy (private classes are in gray):

Users of this hierarchy see only one public class, Number, so how is it possible to allocate instances of the proper subclass? The answer is in the way the abstract superclass handles instantiation.
Creating Instances
The abstract superclass in a class cluster must declare methods for creating instances of its private subclasses. It’s the superclass’s responsibility to dispense an object of the proper subclass based on the creation method that you invoke—you don’t, and can’t, choose the class of the instance.
In the Foundation framework, you generally create an object by invoking a + className... method or the alloc... and init... methods. Taking the Foundation framework’s NSNumber class as an example, you could send these messages to create number objects:
NSNumber *aChar = [NSNumber numberWithChar:’a’]; |
NSNumber *anInt = [NSNumber numberWithInt:1]; |
NSNumber *aFloat = [NSNumber numberWithFloat:1.0]; |
NSNumber *aDouble = [NSNumber numberWithDouble:1.0]; |
(This style of instantiation creates objects that will be deallocated automatically—See “Class Factory Methods” for more information. Many classes also provide the standard alloc... and init... methods to create objects that require you to manage their deallocation.)
Each object returned—aChar, anInt, aFloat, and aDouble—may belong to a different private subclass (and in fact does). Although each object’s class membership is hidden, its interface is public, being the interface declared by the abstract superclass, NSNumber. Although it is not precisely correct, it’s convenient to consider the aChar, anInt, aFloat, and aDouble objects to be instances of the NSNumber class, since they’re created by NSNumber class methods and accessed through instance methods declared by NSNumber.
Class Clusters With Multiple Public Superclasses
In the example above, one abstract public class declares the interface for multiple private subclasses. This is a class cluster in the purest sense. It’s also possible, and often desirable, to have two (or possibly more) abstract public classes that declare the interface for the cluster. This is evident in the Foundation Framework, which includes these clusters:
Class Cluster | Public Superclasses |
|---|---|
| |
| |
| |
| |
Other clusters of this type also exist, but these clearly illustrate how two abstract nodes cooperate in declaring the programmatic interface to a class cluster. In each of these clusters, one public node declares methods that all cluster objects can respond to, and the other node declares methods that are only appropriate for cluster objects that allow their contents to be modified.
This factoring of the cluster’s interface helps make an object-oriented framework’s programmatic interface more expressive. For example, imagine a Book object that declares this method:
- (NSString *)title; |
The book object could return its own instance variable or create a new string object and return that—it doesn’t matter. It’s clear from this declaration that the returned string can’t be modified. Any attempt to modify the returned object will elicit a compiler warning.
Creating Subclasses Within a Class Cluster
The class cluster architecture involves a trade-off between simplicity and extensibility: Having a few public classes stand in for a multitude of private ones makes it easier to learn and use the classes in a framework but somewhat harder to create subclasses within any of the clusters. However, if it’s rarely necessary to create a subclass, then the cluster architecture is clearly beneficial. Clusters are used in the Foundation Framework in just these situations.
If you find that a cluster doesn’t provide the functionality your program needs, then a subclass may be in order. For example, imagine that you want to create an array object whose storage is file-based rather than memory-based, as in the NSArray class cluster. Since you are changing the underlying storage mechanism of the class, you’d have to create a subclass.
On the other hand, in some cases it might be sufficient (and easier) to define a class that embeds within it an object from the cluster. Let’s say that your program needs to be alerted whenever some data is modified. In this case, creating a simple cover for a data object that the Foundation framework defines may be the best approach. An object of this class could intervene in messages that modify the data, intercepting the messages, acting on them, and then forwarding them to the embedded data object.
In summary, if you need to manage your object’s storage, create a true subclass. Otherwise, create a composite object, one that embeds a standard Foundation framework object in an object of your own design. The sections below give more detail on these two approaches.
A True Subclass
A new class that you create within a class cluster must:
Be a subclass of the cluster’s abstract superclass.
Declare its own storage.
Override the superclass’s primitive methods (described below).
Since the cluster’s abstract superclass is the only publicly visible node in the cluster’s hierarchy, the first point is obvious. This implies that the new subclass will inherit the cluster’s interface but no instance variables, since the abstract superclass declares none. Thus the second point: The subclass must declare any instance variables it needs. Finally, the subclass must override any method it inherits that directly accesses an object’s instance variables. Such methods are called primitive methods.
A class’s primitive methods form the basis for its interface. For example, take the NSArray class, which declares the interface to objects that manage arrays of objects. In concept, an array stores a number of data items, each of which is accessible by index. NSArray expresses this abstract notion through its two primitive methods, count and objectAtIndex:. With these methods as a base, other methods—derived methods—can be implemented, for example:
Derived Method | Possible Implementation |
|---|---|
| Find the last object by sending the array object this message: |
| Find an object by repeatedly sending the array object an |
The division of an interface between primitive and derived methods makes creating subclasses easier. Your subclass must override inherited primitives, but having done so can be sure that all derived methods that it inherits will operate properly.
The primitive-derived distinction applies to the interface of a fully initialized object. The question of how init... methods should be handled in a subclass also needs to be addressed.
In general, a cluster’s abstract superclass declares a number of init... and + className methods. As described in “Creating Instances,” the abstract class decides which concrete subclass to instantiate based your choice of init... or + className method. You can consider that the abstract class declares these methods for the convenience of the subclass. Since the abstract class has no instance variables, it has no need of initialization methods.
Your subclass should declare its own init... (if it needs to initialize its instance variables) and possibly + className methods. It should not rely on any of those that it inherits. To maintain its link in the initialization chain, it should invoke its superclass’s designated initializer within its own designated initializer method. (See “The Runtime System“ in The Objective-C 2.0 Programming Language for a discussion of designated initializers.) Within a class cluster, the designated initializer of the abstract superclass is always init.
True Subclasses: An Example
An example will help clarify the foregoing discussion. Let’s say that you want to create a subclass of NSArray, named MonthArray, that returns the name of a month given its index position. However, a MonthArray object won’t actually store the array of month names as an instance variable. Instead, the method that returns a name given an index position (objectAtIndex:) will return constant strings. Thus, only twelve string objects will be allocated, no matter how many MonthArray objects exist in an application.
The MonthArray class is declared as:
#import <foundation/foundation.h> |
@interface MonthArray : NSArray |
{ |
} |
+ monthArray; |
- (unsigned)count; |
- (id)objectAtIndex:(unsigned)index; |
@end |
Note that the MonthArray class doesn’t declare an init... method since it has no instance variables to initialize. The count and objectAtIndex: methods simply cover the inherited primitive methods, as described above.
The implementation of the MonthArray class looks like this:
#import "MonthArray.h" |
@implementation MonthArray |
static MonthArray *sharedMonthArray = nil; |
static NSString *months[] = { @"January", @"February", @"March", |
@"April", @"May", @"June", @"July", @"August", @"September", |
@"October", @"November", @"December" }; |
+ monthArray |
{ |
if (!sharedMonthArray) { |
sharedMonthArray = [[MonthArray alloc] init]; |
} |
return sharedMonthArray; |
} |
- (unsigned)count |
{ |
return 12; |
} |
- objectAtIndex:(unsigned)index |
{ |
if (index >= [self count]) |
[NSException raise:NSRangeException format:@"***%s: index |
(%d) beyond bounds (%d)", sel_getName(_cmd), index, |
[self count] - 1]; |
else |
return months[index]; |
} |
@end |
Since MonthArray overrides the inherited primitive methods, the derived methods that it inherits will work properly without being overridden. NSArray’s lastObject, containsObject:, sortedArrayUsingSelector:, objectEnumerator, and other methods work without problems for MonthArray objects.
A Composite Object
By embedding a private cluster object in an object of your own design, you create a composite object. This composite object can rely on the cluster object for its basic functionality, only intercepting messages that it wants to handle in some particular way. Using this approach reduces the amount of code you must write and lets you take advantage of the tested code provided by the Foundation Framework.
A composite object can be viewed in this way:
The composite object must declare itself to be a subclass of the cluster’s abstract node. As a subclass, it must override the superclass’s primitive methods. It can also override derived methods, but this isn’t necessary since the derived methods work through the primitive ones.
Using NSArray’s count method as an example, the intervening object’s implementation of a method it overrides can be as simple as:
- (unsigned)count |
{ |
return [embeddedObject count]; |
} |
However, your object could put code for its own purposes in the implementation of any method it overrides.
A Composite Object: An Example
To illustrate the use of a composite object, imagine you want a mutable array object that tests changes against some validation criteria before allowing any modification to the array’s contents. The example that follows describes a class called ValidatingArray, which contains a standard mutable array object. ValidatingArray overrides all of the primitive methods declared in its superclasses, NSArray and NSMutableArray. It also declares the array, validatingArray, and init methods, which can be used to create and initialize an instance:
#import <foundation/foundation.h> |
@interface ValidatingArray : NSMutableArray |
{ |
NSMutableArray *embeddedArray; |
} |
+ validatingArray; |
- init; |
- (unsigned)count; |
- objectAtIndex:(unsigned)index; |
- (void)addObject:object; |
- (void)replaceObjectAtIndex:(unsigned)index withObject:object; |
- (void)removeLastObject; |
- (void)insertObject:object atIndex:(unsigned)index; |
- (void)removeObjectAtIndex:(unsigned)index; |
@end |
The implementation file shows how, in a ValidatingArray’s init method, the embedded object is created and assigned to the embeddedArray variable. Messages that simply access the array but don’t modify its contents are relayed to the embedded object. Messages that could change the contents are scrutinized (here in pseudo-code) and relayed only if they pass the hypothetical validation test.
#import "ValidatingArray.h" |
@implementation ValidatingArray |
- init |
{ |
self = [super init]; |
if (self) { |
embeddedArray = [[NSMutableArray allocWithZone:[self zone]] init]; |
} |
return self; |
} |
+ validatingArray |
{ |
return [[[self alloc] init] autorelease]; |
} |
- (unsigned)count |
{ |
return [embeddedArray count]; |
} |
- objectAtIndex:(unsigned)index |
{ |
return [embeddedArray objectAtIndex:index]; |
} |
- (void)addObject:object |
{ |
if (/* modification is valid */) { |
[embeddedArray addObject:object]; |
} |
} |
- (void)replaceObjectAtIndex:(unsigned)index withObject:object; |
{ |
if (/* modification is valid */) { |
[embeddedArray replaceObjectAtIndex:index withObject:object]; |
} |
} |
- (void)removeLastObject; |
{ |
if (/* modification is valid */) { |
[embeddedArray removeLastObject]; |
} |
} |
- (void)insertObject:object atIndex:(unsigned)index; |
{ |
if (/* modification is valid */) { |
[embeddedArray insertObject:object atIndex:index]; |
} |
} |
- (void)removeObjectAtIndex:(unsigned)index; |
{ |
if (/* modification is valid */) { |
[embeddedArray removeObjectAtIndex:index]; |
} |
} |
Creating a Singleton Instance
Some classes of Foundation and the Application Kit create singleton objects: the sole allowable instance of a class in the current process. For example, the NSFileManager and the NSWorkspace classes instantiate singleton objects for use by a process. When you ask for an instance from these classes, they pass you a reference to the sole instance, allocating and initializing it if it doesn’t yet exist.
A singleton object acts as a kind of control center, directing or coordinating the services of the class. Your class should generate a singleton instance rather than multiple instances when there is conceptually only one instance (as with, for example, NSWorkspace). You use singleton instances rather than factory methods or functions when it is conceivable that there might be multiple instances one day.
To create a singleton, you need to do a few things in your code:
Declare a static instance of your singleton object and initialize it to
nil.In your class factory method for the class (named something like “sharedInstance” or “sharedManager”), generate an instance of the class but only if the static instance is
nil.Override the
allocWithZone:method to ensure that another instance is not allocated if someone tries to allocate and initialize an instance of your class directly instead of using the class factory method.Implement the base protocol methods
copyWithZone:,release,retain,retainCount, andautoreleaseto do the appropriate things to ensure singleton status. (The last four of these methods apply to memory-managed code, not to garbage-collected code.)
Listing 2-15 illustrates how you might implement a singleton:
Listing 2-15 Implementation of a singleton
static MyGizmoClass *sharedGizmoManager = nil; |
+ (MyGizmoClass*)sharedManager |
{ |
@synchronized(self) { |
if (sharedGizmoManager == nil) { |
[[self alloc] init]; // assignment not done here |
} |
} |
return sharedGizmoManager; |
} |
+ (id)allocWithZone:(NSZone *)zone |
{ |
@synchronized(self) { |
if (sharedGizmoManager == nil) { |
sharedGizmoManager = [super allocWithZone:zone]; |
return sharedGizmoManager; // assignment and return on first allocation |
} |
} |
return nil; //on subsequent allocation attempts return nil |
} |
- (id)copyWithZone:(NSZone *)zone |
{ |
return self; |
} |
- (id)retain |
{ |
return self; |
} |
- (unsigned)retainCount |
{ |
return UINT_MAX; //denotes an object that cannot be released |
} |
- (void)release |
{ |
//do nothing |
} |
- (id)autorelease |
{ |
return self; |
} |
Situations could arise where you want a singleton instance (created and controlled by the class factory method) but also have the ability to create other instances as needed through allocation and initialization. In these cases, you would not override allocWithZone: and the other methods following it as shown in Listing 2-15.
© 2008 Apple Inc. All Rights Reserved. (Last updated: 2008-11-19)