Security Concepts
This chapter introduces several concepts necessary to understanding the Mac OS X and iPhone OS security APIs. It does not explain any of these concepts in depth, provide programming algorithms, or give the mathematical foundations of cryptography. If you are already familiar with security concepts, you may skip this chapter. If you are already familiar with security concepts in general but would like to know more about how permissions are implemented in Mac OS X, see “Permissions.”
For references to more detailed sources of information on security concepts and on how to write secure applications, see “See Also.”
In this section:
Aspects of Security
Authentication, Identification, and Authorization
Encryption and Decryption
Encrypting Messages
Digital Signatures
Digital Certificates
Authentication and Identification Methods
Permissions
Authorization
Secure Storage
Secure Communication
Aspects of Security
The fundamental purpose of security is to control who has access to valuable property, whether physical or intellectual. This is the reason we have locks on the doors of our houses, why the military encrypts classified information, and why Mac OS X and iPhone OS enable users to require a password or PIN every time someone logs on to their computer, iPhone, or iPod Touch.
Security features on a personal computer can be classified into two general groups: those designed to protect programs and data on the computer from unauthorized access by users on the system (“local security”); and those designed to protect the system, programs, and data from unauthorized access over a network or other transport medium, such as removable disks (“remote transport security”).
When considering local security, you must be aware of whether access is being controlled by the operating system or by the application itself.
Local Security
Local security is important when a computer is being shared, such as in libraries or schools; or when an unauthorized person might get access to the computer, such as a computer kept in an open cubicle in a large office. Security features useful in such environments include the password protection offered by the Finder, encryption of data provided by FileVault, BSD access permissions, and access permissions added to applications through use of Authorization Services.
Remote Transport Security
Remote transport security is important to all users, and especially to users whose computers are connected to a LAN or to the Internet. Web browsers, for example, use secure transport protocols (“Protocols for Secure Communication”) to protect data from interception while in transit, digital signatures (“Digital Signatures”) to ensure data integrity, and digital certificates (“Digital Certificates”) to verify the identity of people or servers trying to get access to data. Many of the security APIs provided by Mac OS X and iPhone OS are useful in this regard, including the secure networking APIs (Secure Transport, CFNetwork, and URL Loading System), Keychain Services (used to store certificates, passwords, and encryption keys), and Certificate, Key, and Trust Services.
System-Restricted or Self-Restricted Access
It is important to understand that certain forms of access permission are enforced by the operating system, whereas others are enforced by individual applications. BSD permissions (“BSD”) control who can execute a program or open a file, and are built into the operating system. On the other hand, if you want finer-grained control over access, such as restricting certain operations to a subset of users, you must enforce these restrictions yourself. Authorization Services provides functions you can use to implement such restrictions, and you can make the restrictions optional so that they operate only when your application is being used in an environment where they are necessary. For example, you might want to restrict access to some application preferences to administrators on a shared computer but not require a password when the computer is not shared. See Authorization for Everyone, Technical Note TN2095, for techniques and sample code for implementing self-restricted access permissions.
Authentication, Identification, and Authorization
Authentication is the process by which a person or other entity (such as a server) proves that it is who (or what) it says it is. Authentication is achieved through presenting something that you know, something that you have, some unique identifying feature, or some combination of these. A common example is the way you authenticate yourself in order to use a teller machine: you insert your ATM card (something you have) and enter your personal identification number (PIN, something you know). Unique identifying features include such things as fingerprints, retina patterns, and voice prints.
It is always desirable to authenticate the person or server with which you are dealing before transferring something valuable, such as information or money. Authentication, however, is time consuming and can inconvenience users. For example, once having shown your photo ID card to enter the Apple Worldwide Developer’s Conference, you would not want to get it out again every time you walked into one of the conference rooms. To make situations like this more convenient and efficient, many systems use some method of identification, which verifies that the person or entity is the same one you communicated with last time. The means of identification can be through the use of a ticket or token issued when authentication is done. For example, the conference badge you are given to wear during the Developer’s Conference identifies you as a legitimate attendee who was authenticated when you first came in.
In general, authentication or identification is not sufficient to gain access to information or code. For that, the entity requesting access must have authorization. Authorization requires first a determination that the authenticated entity has the appropriate permissions—that is, the right to the specific type of access (such as read, write, or execute) requested—and then the actual granting of that access. For example, the mere possession of a conference badge does not grant you the right to enter a restricted area, such as the speakers’ preparation room. You must have permission to enter this area (indicated, in this case, by the color of your badge), and you must be granted access by the guard at the door.
Authentication and identification methods available in Mac OS X are described in “Authentication and Identification Methods.” Permissions in BSD and Mac OS X are described in “Permissions.” Authorization is discussed in more detail in “Authorization.” Note that iPhone OS relies on the device’s PIN and the sandboxing (“Sandboxing and the Mandatory Acccess Control Framework”) of applications to provide security—no authorization or authentication interface is provided for iPhone OS.
Encryption and Decryption
Most of the security APIs in Mac OS X and iPhone OS rely to some degree on encryption of text or data. For example, encryption is used in the creation of certificates and digital signatures, in secure storage of secrets in the keychain, and in secure transport of information. For the purposes of this book, encryption is defined as the transformation of data into a form in which it cannot be made sense of without the use of some key. Such transformed data is referred to as ciphertext. Use of a key to reverse this process and return the data to its original (or plaintext) form is called decryption.
Encryption can be anything from a simple process of substituting one character for another—in which case the key is the substitution rule—to a complex mathematical algorithm. For purposes of security, the more difficult it is to decrypt the ciphertext, the better. On the other hand, if the algorithm is too complex, takes too long to do, or requires keys that are too large to store easily, it becomes impractical for use in a personal computer. Therefore, some balance must be reached between strength of the encryption (that is, how difficult it is for someone to discover the algorithm and the key) and ease of use.
For practical purposes, the encryption need only be strong enough to protect the data for the amount of time the data might be useful to a person with malicious intent. For example, if you need to keep your bid on a contract secret only until after the contract has been awarded, an encryption method that can be broken in a few weeks will suffice. If you are protecting your credit card number, you probably want an encryption method that cannot be broken for many years.
There are two main types of encryption in use in computer security, referred to as symmetric key encryption and asymmetric key encryption. A closely related process to encryption, in which the data is transformed using a key and a mathematical algorithm that cannot be reversed, is called cryptographic hashing. The remainder of this section discusses encryption keys, key exchange mechanisms (including the Diffie-Hellman key exchange used in some Mac OS X secure transport protocols), and cryptographic hash functions.
Symmetric Keys
Symmetric key cryptography (also called private key cryptography or secret key cryptography) is the classic use of keys that most people are familiar with: the same key is used to encrypt and decrypt the data. The classic, and most easily breakable, version of this is the Caesar cipher (named for Julius Caesar), in which each letter in a message is replaced by a letter that is a fixed number of positions away in the alphabet (for example, “a” is replaced by “c”, “b” is replaced by “d”, and so forth). In this case, the key used to encrypt and decrypt the message is simply the number of positions in the alphabet to shift the letters. Modern symmetric key algorithms are much more sophisticated and much harder to break. However, they share the property of using the same key for encryption and decryption.
There are many different algorithms used for symmetric key cryptography, offering anything from minimal to nearly unbreakable security. Some of these algorithms offer strong security, easy implementation in code, and rapid encryption and decryption. Such algorithms are very useful for such purposes as encrypting files stored on a computer to protect them in case an unauthorized individual uses the computer. They are somewhat less useful for sending messages from one computer to another, because both ends of the communication channel must possess the key and must keep it secure. Distribution and secure storage of such keys can be difficult and can open security vulnerabilities.
In 1968, the USS Pueblo, a U.S. Navy intelligence ship, was captured by the North Koreans. At the time, every Navy ship carried symmetric keys for a variety of code machines at a variety of security levels. Each key was changed daily. Because there was no way to know how many of these keys had not been destroyed by the Pueblo’s crew and therefore were in the possession of North Korea, the Navy had to assume that all keys being carried by the Pueblo had been compromised. Every ship and shore station in the Pacific theater (that is, several thousand installations, including ships at sea) had to replace all of their keys by physically carrying code books and punched cards to each installation.
The Pueblo incident was an extreme case. However, it has something in common with the problem of providing secure communication for commerce over the Internet. In both cases, codes are used for sending secure messages, not between two locations, but between a server (the Internet server or the Navy’s communications center) and a large number of communicants (individual web users or ships and shore stations). The more end users that are involved in the secure communications, the greater the problems of distribution and protection of the secret symmetric keys.
Although secure techniques for exchanging or creating symmetric keys can overcome this problem to some extent (see, for example, “Diffie-Hellman Key Exchange”), a more practical solution for use in computer communications came about with the invention of practical algorithms for asymmetric key cryptography.
Asymmetric Keys
In asymmetric key cryptography, different keys are used for encrypting and decrypting a message. The asymmetric key algorithms that are most useful are those in which neither key can be deduced from the other. In that case, one key can be made public while the other is kept secure. There are some distinct advantages to this public-key–private-key arrangement, often referred to as public key cryptography: the necessity of distributing secret keys to large numbers of users is eliminated, and the algorithm can be used for authentication as well as for cryptography.
The first public key algorithm to become widely available was described by Ron Rivest, Adi Shamir, and Len Adleman in 1977, and is known as RSA encryption from their initials. Although other public key algorithms have been created since, RSA is still the most commonly used. The mathematics of the method are beyond the scope of this document, and are available on the Internet and in many books on cryptography. The algorithm is based on mathematical manipulation of two large prime numbers and their product. Its strength is believed to be related to the difficulty of factoring a very large number. With the current and foreseeable speed of modern digital computers, the selection of long-enough prime numbers in the generation of the RSA keys should make this algorithm secure indefinitely. However, this belief has not been proved mathematically, and either a fast factorization algorithm or an entirely different way of breaking RSA encryption might be possible. Also, if practical quantum computers are developed, factoring large numbers will no longer be an intractable problem.
Other public key algorithms, based on different mathematics of equivalent complexity to RSA, include ElGamal encryption and elliptic curve encryption. Their use is similar to RSA encryption (though the mathematics behind them differs), and they will not be discussed further in this document.
To see how public key algorithms address the problem of key distribution, assume that Alice wants to receive a secure communication from Bob. The procedure is illustrated in Figure 2-1.
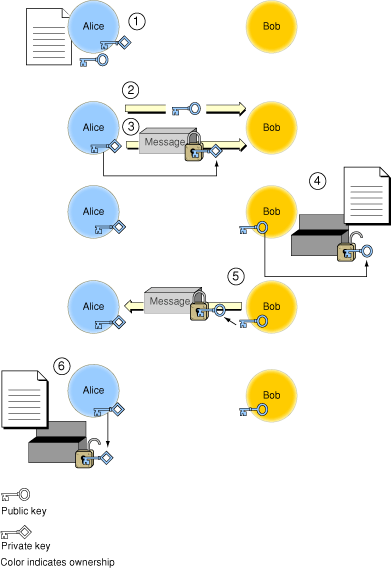
The secure message exchange illustrated in Figure 2-1 has the following steps:
Alice uses one of the public key algorithms to generate a pair of encryption keys: a private key, which she keeps secret, and a public key. She also prepares a message to send to Bob.
Alice sends the public key to Bob, unencrypted. Because her private key cannot be deduced from the public key, doing so does not compromise her private key in any way.
Alice can now easily prove her identity to Bob (a process known as authentication). To do so, she encrypts her message (or any portion of the message) using her private key and sends it to Bob.
Bob decrypts the message with Alice’s public key. This proves the message must have come from Alice, as only she has the private key used to encrypt it.
Bob encrypts his message using Alice’s public key and sends it to Alice. The message is secure, because even if it is intercepted, no one but Alice has the private key needed to decrypt it.
Alice decrypts the message with her private key.
Since encryption and authentication are subjects of great interest in national security and protecting corporate secrets, some extremely smart people are engaged both in creating secure systems and in trying to break them. Therefore, it should come as no surprise that actual secure communication and authentication procedures are considerably more complex than the one just described. For example, the authentication method of encrypting the message with your private key can be got around by a man-in-the-middle attack, where someone with malicious intent (usually referred to as Eve in books on cryptography) intercepts Alice’s original message and replaces it with their own, so that Bob is using not Alice’s public key, but Eve’s. Eve then intercepts each of Alice’s messages, decrypts it with Alice’s public key, alters it (if she wishes), and reencrypts it with her own private key. When Bob receives the message, he decrypts it with Eve’s public key, thinking that the key came from Alice.
Although this is a subject much too broad and technical to be covered in detail in this document, see “Digital Certificates,” “Digital Signatures,” and “Authentication and Identification Methods” for a few of the approaches used to address these security problems.
Diffie-Hellman Key Exchange
The Diffie-Hellman key exchange protocol is a way for two ends of a communication session to generate symmetric private keys through the exchange of public keys. The two sides agree beforehand on the exact algorithm to use and certain parameters, such as the size of the keys. Then each side selects a random number as a private key and uses that number to generate a public key, according to the algorithm. The security of this algorithm depends in part on it being extremely difficult to derive or guess the private key from this public key.
The two sides exchange public keys and then each generates a session key using their own private key and the other side’s public key. The mathematics of the algorithm is such that, even though neither side knows the other side’s private key, both sides’ session keys are identical. A third party intercepting the public keys but lacking knowledge of either private key cannot generate a session key. Therefore, data encrypted with the session key is secure while in transit.
Although Diffie-Hellman key exchange provides strong protection against compromise of intercepted data, it provides no mechanism for ensuring that the entity on the other end of the connection is who you think it is. That is, this protocol is vulnerable to a man-in-the-middle attack. Therefore, it is sometimes used together with some other authentication method to ensure the integrity of the data.
Diffie-Hellman key exchange is supported by Apple Filing Protocol (AFP) version 3.1 and later and by Apple’s Secure Transport API. Because RSA encryption tends to be slower than symmetric key methods, Diffie-Hellman (and other systems where public keys are used to generate symmetric private keys) can be useful when a lot of encrypted data must be exchanged.
Cryptographic Hash Functions
A cryptographic hash function takes any amount of data and applies an algorithm that transforms it into a fixed-size output value. For a cryptographic hash function to be useful, it has to be extremely difficult or impossible to reconstruct the original data from the hash value, and it must be extremely unlikely that the same output value could result from any other input data.
Sometimes it is more important to verify the integrity of data than to keep it secret. For example, if Alice sent a message to Bob instructing him to shred some records (legally, of course), it would be important to Bob to verify that the list of documents was accurate before proceeding with the shredding. Since the shredding is legal, however, there is no need to encrypt the message, a computationally expensive and time-consuming process. Instead, Alice could compute a hash of the message (called a message digest) and encrypt the digest with her private key. When Bob receives the message, he decrypts the message digest with Alice’s public key (thus verifying that the message is from Alice), and computes his own message digest from the message text. If the two digests match, then Bob knows the message has not been corrupted or tampered with. For more information on ensuring data integrity, see “Digital Signatures”
Commonly used hash functions include MD5, from RSA Data Security, which hashes any amount of input data into a 128-bit output value, and SHA-1, developed and published by the U.S. Government, which produces a 160-bit hash value from any data up to 264 bits in length.
Encrypting Messages
Either symmetric or asymmetric key methods can be used to encrypt messages. Whereas the iPhone OS Certificate, Key, and Trust Services API includes functions to encrypt and decrypt data, Mac OS X does not provide a high-level encryption API. In Mac OS X, you can call CSSM Cryptographic Services Manager functions to encrypt data. See “CDSA” and “CSSM Services” for more information about CSSM. For examples of code using CSSM for common encryption tasks, see the CryptoSample sample code.
Apple’s Mail application (and other email applications) can extract a public key from the signing certificate of any signed email and use it to encrypt messages sent to the owner of that key. See “Digital Signatures” for more information about digital signatures and Help for the Mail application for details on sending encrypted email.
If you use the Secure Transport or CFNetwork APIs to set up a secure communication session, all data sent over that communication link is encrypted. See “Secure Communication” for more information.
Digital Signatures
Digital signatures are a way to ensure the integrity of a message or other data using public key cryptography. Like traditional signatures written with ink on paper, they can be used to authenticate the identity of the signer of the data. However, digital signatures go beyond traditional signatures in that they can also ensure that the data itself has not been altered. This is like signing a check in such a way that if someone changes the amount of the sum written on the check, an “Invalid” stamp becomes visible on the face of the check.
To create a digital signature, the signer generates a message digest of the data and then uses a private key to encrypt the digest. The signature includes the encrypted digest and information about the signer’s digital certificate. The certificate is used to verify the signature; it includes the public key needed to decrypt the digest and the algorithm used to create the digest. To verify that the signed document has not been altered, the recipient uses the algorithm to create their own message digest and uses the public key to decrypt the digest in the signature. If the two digests are identical, then the message cannot have been altered and must have been sent by the owner of the public key.
To ensure that the person who provided the signature is not only the same person who provided the data but is also who they say they are, the certificate is also signed—in this case by the certification authority who issued the certificate. Digital certificates are described in “Digital Certificates.” Starting with Mac OS X v10.5, developers are encouraged to sign their applications. On execution, each application’s signature is checked for validity. Digital signatures are required on all applications for iPhone OS. See “Code Signing” for more information on how code signing is used by Mac OS X and iPhone OS.
Figure 2-2 illustrates the creation of a digital signature.
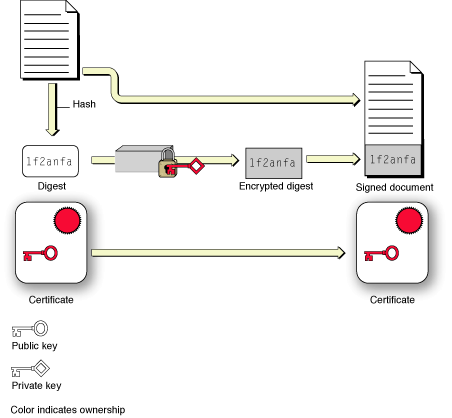
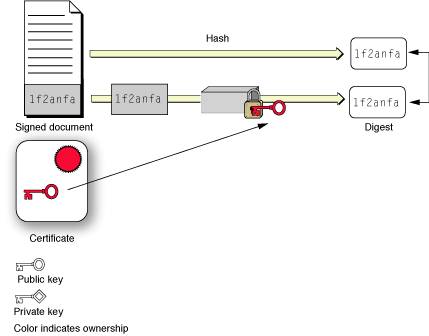
Figure 2-3 illustrates the verification of a digital signature. The recipient gets the signer’s public key from the signer’s certificate and uses that to decrypt the digest. Then, using the algorithm indicated in the certificate, the recipient creates a new digest of the data and compares the new digest to the decrypted copy of the one delivered in the signature. If they match, then the received data must be identical to the original data created by the signer.
Digital Certificates
A digital certificate is a collection of data used to verify the identity of the holder or sender of the certificate. For example, an X.509 certificate contains such information as:
Version
Serial number
Certificate issuer
Certificate holder
Validity period (the certificate is not valid before or after this period)
Attributes, known as certificate extensions, that contain additional information such as allowable uses for this certificate
Digital signature from the certification authority to ensure that the certificate has not been altered and to indicate the identity of the issuer
Public key of the owner of the certificate
Message digest algorithm used to create the signature
The careful reader will have noticed that a digital signature indicates the certificate of the signer, and a certificate contains a digital signature, which indicates another certificate. In general, each certificate is verified through the use of another certificate, creating a chain of certificates that ends with the root certificate. The issuer of a certificate is called a certification authority (CA). The owner of the root certificate is the root certification authority. Figure 2-4 illustrates the anatomy of a digital certificate.
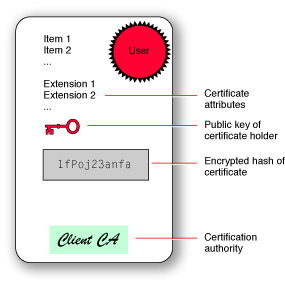
The root certificate is self-signed, meaning the signature of the root certificate was created by the root certification authority themselves. Figure 2-5 and Figure 2-6 illustrate how a chain of certificates is created and used. Figure 2-5 shows how the root certification authority creates its own certificate and then creates a certificate for a secondary certification authority.
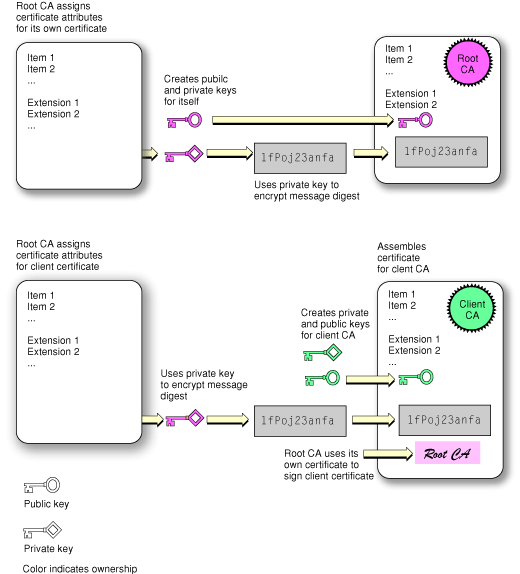
Figure 2-6 shows how the secondary certification authority creates a certificate for an end user and how the end user uses it to sign a document.
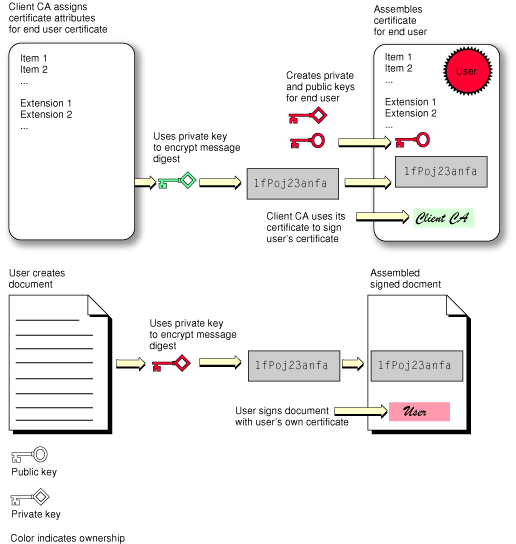
In Figure 2-6, the creator of the document has signed the document. The signature indicates the certificate of the document’s creator (labeled “User” in the figure). The document’s creator signs the document with a private key, and the signing certificate contains the corresponding public key, which can be used to decrypt the message digest to verify the signature (see “Digital Signatures.” This certificate—together with the private and public keys—was provided by a certification authority (CA). In order to verify the validity of the user’s certificate, the certificate is signed using the certificate of the CA. The certificate of the CA includes the public key needed to decrypt the message digest of the user’s certificate. Continuing the certificate chain, the certificate of the CA is signed using the certificate of the authority who issued that certificate. The chain can go on through any number of intermediate certificates, but in Figure 2-5 the issuer of the CA’s certificate is the root certification authority. Note that the certificate of the root CA, unlike the others, is “self signed.” That is, it does not refer to a further certification authority but is signed using the root CA’s own private key.
When a CA creates a certificate, it uses its private key to encrypt the certificate’s message digest. The signature of every certificate the CA issues refers to its own signing certificate. The CA’s public key is in this certificate, and the application verifying the signature must extract this key to verify the certificate of the CA. So it continues, on down the certificate chain, to the certificate of the root CA. When a root CA issues a certificate, it, too, signs the certificate. However, this signing certificate was not issued by another CA; the chain stops here. Rather, the root CA issues its own signing certificate, as shown in Figure 2-5.
The certificate of the root CA can be verified by creating a digest and comparing it with one widely available. Typically, the root certificate and root CA’s public key are already stored in the application or on the computer that needs to verify the signature.
It’s possible to end a certificate chain with a trusted certificate that is not a root certificate. For example, a certificate can be certified as trusted by the user, or can be cross certified—that is, signed with more than one certificate chain. The general term for a certificate trusted to certify other certificates—including root certificates and others—is anchor certificate. Because most anchor certificates are root certificates, the two terms are often used interchangeably.
The confidence you can have in a given certificate depends on the confidence you have in the anchor certificate; for example, the trust you have in the certificate authorities and in their procedures for ensuring that subsequent certificate recipients in the certificate chain are fully authenticated. For this reason, it is always a good idea to examine the certificate that comes with a digital signature, even when the signature appears to be valid. In Mac OS X and iPhone OS, all certificates you receive are stored in your keychain. In Mac OS X, you can use the Keychain Access utility to view them.
Certain attributes of a digital certificate (known as certificate extensions) are said to establish a level of trust for a digital certificate. A trust policy is a set of rules that specify the appropriate uses for a certificate that has a specific level of trust. In other words, the level of trust for a certificate is used to answer the question “Should I trust this certificate for this action?”
For example, the AppleX509TP module (“AppleX509TP Module”) enforces a trust policy referred to as the S/MIME policy, which specifies that in order to be trusted to verify a digitally signed email, a certificate must contain an email address that matches the address of the sender of the email.
Authentication and Identification Methods
This section describes some of the authentication and identification methods used in software in general and in Mac OS X in particular, but gives no implementation details or programming samples.
If you use Authorization Services, your application can take advantage of any authentication methods supported by Mac OS X, even if new methods are added after you write your code. See “Authorization Services” for more information on Mac OS X Authorization Services.
Mac OS X
Mac OS X servers and clients can authenticate users by:
Using the Kerberos Key Distribution Center (KDC), which is built into Mac OS X Server (see “Kerberos”)
Using a password stored securely in the Open Directory Password Server database
Using shadow hash authentication, in which cryptographic hashes for NT and LAN Manager authentication are stored in a local file that only the root user can access
Using an encrypted password stored directly in the user’s account
Using a non-Apple LDAP (Lightweight Directory Access Protocol) server
Shared Secret
Many authentication methods are based on shared secrets, such as passwords. The security of shared secret authentication methods depends on the ability of both parties to keep the secret safe. If the secret is ever intercepted or is simple enough to be easily guessed, the method is not secure at all. The physicist Richard Feynman had a reputation as a safecracker when he worked at Los Alamos. However, in most instances he merely guessed the safe’s combination by using such numbers as the safe owner’s birthday or address. Similarly, if you select a password based on your middle name and then use the same password on all your accounts, none of the accounts will be secure.
On the other hand, carefully picked and guarded secrets can be extremely secure. Two examples of highly secure shared secret methods are one-time pads and time-based passwords.
One-Time Pads
One-time pad authentication requires that both parties have an identical list of pairs of numbers, words, or symbols. The most secure lists are randomly generated. When one party (Alice) requests an interchange with the other (Bob), Bob sends Alice a challenge in the form of one of the items selected from the list. Alice must respond with the corresponding paired item (Figure 2-7). Once a challenge has been used, it is crossed off the list and never used again.
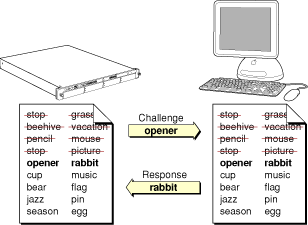
The one-time nature of one-time pad authentication makes it impossible for someone to guess the appropriate response to any one particular challenge by a brute force attack—that is, by responding to the challenge repeatedly with different answers until hitting the right answer. Similarly, it is impossible to guess what the next challenge should be. Assuming that the lists are truly randomly generated, the only way to break such a system is to know some portion of the contents of the list of pairs.
For this reason, once the one-time pad has been shared securely, it can be used over insecure communication channels. If someone snoops the communication, they can obtain that challenge-response pair. However, that information is of no use to them, since that particular challenge is never issued again.
The first problem with challenge-response pairs is that generating truly random lists is difficult with computers. Pseudorandom lists are much easier to obtain, and can (in principle at least) be duplicated, given the right algorithm and a good guess at the seed value. The second problem is that this method is useful only if every pair of correspondents has a unique set of lists. Otherwise, it is impossible to determine which holder of the list is authenticating. Finally, as with any shared secret method, the lists must be kept secret when they are shared and stored securely. If one of the lists is obtained by a third party, the method is compromised and the security breach might be undetectable.
Time-Based Authentication
Time-based authentication is a shared secret method in which the secret is changed periodically in a way known only to the two parties involved. In one variant, both parties begin with the same small amount of seed numbers (as few as two or three) and use a mathematical function that calculates a new number from them. Every time interval (for example, once a minute), a new number is calculated from the previous two or three numbers and the oldest number is discarded.
As long as both parties keep their clocks synchronized and start with the same seed numbers, they can calculate the current authentication number. In order to guard against a third party intercepting enough numbers to calculate the series or authenticating themselves before the number expires, the numbers should be transmitted over a secure communication channel. To further increase security (for example, if the number-generating ID card is lost or stolen), the generated number is combined with a password or PIN known only to the two parties.
As with other shared secret methods, time-based authentication depends on the physical security of the shared secret, and each individual wishing to use the system must have a unique generated number and PIN.
Kerberos
In Greek mythology, Kerberos was the three-headed dog that guarded the gates of Hades. In computer security, Kerberos is an industry-standard protocol created by the Massachusetts Institute of Technology (MIT) to provide authentication over a network. Kerberos is a symmetric-key, server-based protocol and is used widely in Macintosh, Windows, and UNIX networks. Kerberos has been integrated into Mac OS X since Mac OS X v10.1. Kerberos is highly secure, and unlike some other shared secret, private-key methods, it can be used for one-to-many and many-to-many communications as well as one-to-one. Kerberos achieves this ability by storing all users’ passwords in a central location, the directory server. Mac OS X works with all common directory servers, including LDAP (Lightweight Directory Access Protocol) servers and Microsoft Windows Active Directory servers. Mac OS X Server v10.3 and later includes an open-source LDAP server. Mac OS X Server v10.2 and later can host Kerberos authentication services (called a Kerberos Key Distribution Center (KDC)). Furthermore, a Mac OS X Server v10.3 or later installation that is configured to include a shared LDAP server automatically includes a Kerberos KDC. Mac OS X Server v10.3 and later uses Kerberos v5. Starting with Mac OS X v10.5, Kerberos client and server implementations are both included in the operating system, so any user’s computer can be configured as a KDC.
Although users’ passwords cannot be intercepted during authentication (because they are never sent over the network), it is very important to keep the machine containing the directory server in a secure location. All passwords and private encryption keys are stored in the directory server and are therefore vulnerable to attack if a malicious person gains access to the server.
Starting with Mac OS X v10.5, a user with a .Mac account can use Kerberos over the internet to access and control a computer remotely, a service known as Back To My Mac. This service uses public key cryptography to authenticate the two computers, which then follow standard Kerberos protocols, with one computer acting as the KDC and the other as the Kerberos client. The protocol that defines the use of public key cryptography for initial authentication in Kerberos is known as PKINIT. You use the open-source Generic Security Service Application Program Interface (GSS-API) to adapt your application to use Kerberos.
Kerberos tickets are blocks of data used to identify a user who has been previously authenticated. Because Kerberos uses tickets (which are issued for a specific user, service, and period of time), it is possible to access additional kerberized services without requiring the user to reauthenticate (by reentering their password). This feature is called single signon. A kerberized service is one that has been configured to take Kerberos tickets.
For more information on Kerberos in Mac OS X, see http://developer.apple.com/opensource/kerberosintro.html. For general information on Kerberos, see http://web.mit.edu/kerberos/. For information on MIT’s Kerberos for Macintosh, see http://web.mit.edu/macdev/Development/MITKerberos/MITKerberosLib/Common/Documentation/KerberosFramework.html. Kerberos version 5 is defined in RFC 4120; PKINIT is defined in RFC 4556; and GSS-API is defined in RFC 2078.
As of Mac OS X v10.5, these Mac OS X services support Kerberos authentication:
Apple Mail
Apple Filing Protocol (AFP server)
Apple FTP server
Telnet
SSH
NFS
SMB
CUPS
VNC
iCal
Xgrid
Macintosh Manager Client Logins
See Mac OS X Server Open Directory Administration (at http://www.apple.com/server/documentation/) to learn about the services that support Kerberos and to learn how to implement a Kerberos KDC on your Mac OS X server.
Kerberos Authentication Process
There are several phases to Kerberos authentication. In the first phase, the client obtains credentials (blocks of data that identify and authenticate an entity) to be used to request access to kerberized services. In the second phase, the client requests authentication for a specific service. In the final phase, the client presents those credentials to the service. Figure 2-8 and Figure 2-9 illustrate this process.
Figure 2-8 shows the first phase, in which the client, labeled Alice in the figure, requests credentials from the Kerberos KDC.
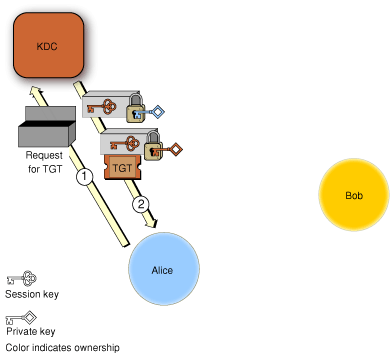
The steps are as follows:
Alice sends a request to the KDC for credentials. The KDC prompts Alice for a user name and password (or other authentication information), checks the authentication information against the data in the directory server, and (assuming the authentication is valid) gets Alice’s private key from the directory server.
The KDC creates an encryption key (called a session key) for use by Alice the next time she wants to request service from a kerberized server and encrypts the key with Alice’s private key. It also creates an identification credential called a ticket-granting ticket (TGT), which contains a copy of the session key encrypted with the KDC’s private key (plus other information). The KDC sends both credentials to Alice. Alice decrypts the session key and stores it for later. She can’t decrypt the TGT or modify it, but saves it for later use as well. Both the session key and the TGT include timestamps and expiration times to limit the chances of their being intercepted and used by unauthorized persons.
In the second phase, Alice uses the TGT to request identification credentials from the KDC in order to use a kerberized service, labeled Bob in the figure. Because Alice has a TGT, the KDC does not have to reauthenticate her, so Alice is not asked again for her password. In the third phase, Alice sends the credentials to Bob, and Bob sends authentication information to Alice. The second and third phases are illustrated in Figure 2-9.
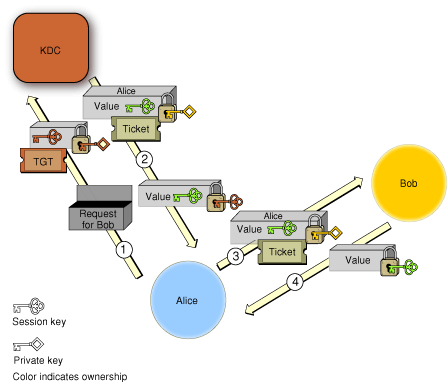
The steps are as follows:
Alice sends to the KDC a request to open a session with Bob, together with the TGT that the KDC issued earlier. Because the TGT is encrypted with the KDC’s private key, it cannot have been altered, and the KDC accepts it as proof that Alice has been authenticated.
The KDC decrypts the TGT and extracts the session key it issued earlier to Alice. (Recall that when the KDC sent the session key to Alice earlier, it was encrypted with Alice’s private key, so only the KDC and Alice can know this session key.) The KDC then generates a random value, encrypts it with the session key, and sends it to Alice. It also creates a ticket for Alice to send to Bob. This ticket contains a new session key, the same random value that was sent to Alice, and an indication that the request for a session came from Alice. This key is encrypted with Bob’s private key, so Alice (or an intruder) cannot read or modify it. The KDC sends the ticket to Alice.
Alice sends the ticket to Bob. Bob decrypts it with his private key. Because only the KDC and Bob know this key, Bob knows the ticket was issued by the KDC. Bob extracts the random value and the session key, and encrypts the random value with the session key.
Bob sends the encrypted value to Alice. Because Alice knows that only she and Bob have this session key, she knows that the credential must have come from Bob. She checks the value and compares it with the one she received earlier from the KDC. If they match, she knows the message was not interfered with, and she accepts that Bob has been authenticated by the KDC.
Note that this procedure does not involve sending either Alice’s or Bob’s private key over the network. Both Alice and Bob are authenticated to each other, so Bob knows that Alice is a valid user and Alice knows that Bob is the server with which she intended to do business. All credentials are further protected with timestamps and expiration times. Kerberos has other security features as well; for details, see the MIT Kerberos website at http://web.mit.edu/kerberos/.
Kerberos and Authorization
Kerberos is an authentication protocol, not an authorization protocol. That is, it verifies the identities of both the client and the server, but it does not include any information about whether the client has a right to use the services provided by the server. In terms of the preceding discussion, once Bob is satisfied that the request for services really came from Alice, it is up to Bob to determine whether to grant Alice access to those services. The ticket that Bob receives from Alice contains enough information about Alice to enable Bob to make that determination.
Starting with Kerberos version 5, Kerberos tickets provide a mechanism for the tamperproof transmission of authorization information. When the client requests a ticket, it includes information about itself in the request and can request that the KDC include additional authorization in the ticket. The KDC inserts this information into the authorization data field of the ticket and forwards it to the server. Kerberos does not define how this authorization information should be encoded; it provides only a secure mechanism for its transmission. It is up to the client and server to implement the authorization protocol.
Single Signon
Mac OS X uses Kerberos for single signon authentication, which relieves users from entering a name and password separately for every kerberized service. With single signon, after a user enters a name and password in the login window, the user does not have to enter a name and password for Apple file service, mail service, or other services that use Kerberos authentication. In other words, Kerberos authenticates the user once, and thereafter uses tickets to identify the user (see “Authentication, Identification, and Authorization”).
To take advantage of the single signon feature, services must be configured for Kerberos authentication and users and services must use the same Kerberos KDC. For Mac OS X Server v10.3 and later, user accounts in an LDAP directory that have a password type of Open Directory use the server’s built-in KDC. These user accounts are automatically configured for Kerberos and single signon. The server’s kerberized services also use the server’s built-in KDC and are automatically configured for single signon. See Mac OS X Server Open Directory Administration (at http://www.apple.com/server/documentation/) for details.
Large Networks
In “Kerberos Authentication Process,” the Kerberos Key Distribution Center (KDC) is treated as a single entity. However, a KDC consists of two separate software processes: the ticket-granting server and the authentication server. The authentication server verifies a user’s identity by prompting the user for a name and password and asking the directory server for the user’s password. The authentication server then looks up the user’s private key, generates a session key, and creates the ticket-granting ticket (TGT), as shown in Figure 2-8. Thereafter, the user sends the TGT to the ticket-granting server whenever the services of a kerberized server are required, and the ticket-granting server issues the ticket, as shown in Figure 2-9.
Many networks are too large to efficiently store all the information about users and computers in a single directory server. Instead, a distributed model is used, where there are a number of directory servers, each serving a subset of the network. In Kerberos parlance, this subset is referred to as a realm. Each realm has its own ticket-granting server and authentication server. If a user needs a ticket for a service in a different realm, the authentication server issues a TGT and the user sends the TGT to the authentication server, as before. The authentication server then issues a ticket, not for the desired service but for the remote ticket-granting server for the realm that the service is in. The user then sends the ticket to the remote ticket-granting server to get the ticket for the actual service.
In fact, in a large network, the user might have to contact the remote ticket-granting server in a sequence of realms before finally getting the ticket for the desired service. When a ticket for the application service is finally issued, it contains an enumeration of all the realms consulted in the process of requesting the ticket. An application server that applies strict authorization rules is permitted to reject authentication that passes through realms that it does not trust.
Although limited cross-realm authentication was possible in Kerberos v4, the full implementation of this feature is new in Kerberos v5.
Public Keys
In public key cryptography, different keys are used for encryption and decryption. One, the private key, is kept secure. The public key, on the other hand, can be made publicly available without compromising the private key or the encryption method. In principle, public key authentication works in much the same way as private key authentication, with one major difference: because public keys do not have to be kept secret, there is no need to encrypt them or send them over secure channels. The public key can be provided by a server, in a certificate, or through some other method. Figure 2-10 illustrates public key authentication using an authentication server.
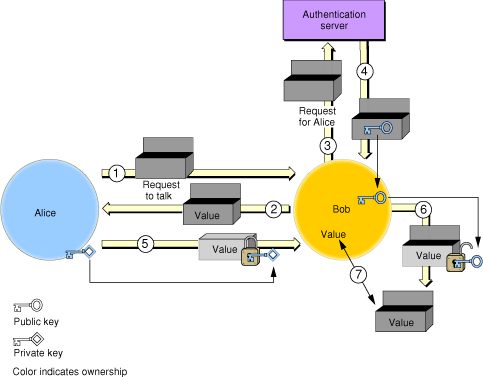
The steps are as follows:
Alice sends Bob a request to talk.
Bob generates a random value and sends it to Alice as a challenge.
Bob requests Alice’s public key from the authentication server.
The authentication server sends the unencrypted public key to Bob.
Alice encrypts the random value with her private key and sends it to Bob.
Bob decrypts the value with Alice’s public key.
Bob compares the decrypted value with the original value to verify that they are identical. Alice has now authenticated herself to Bob.
Bob can authenticate himself to Alice in exactly the same way.
Notice that there is no need for the authentication server to store any sensitive material: the public keys do not have to be stored securely, and the authentication server does not need to hold passwords because it never has to verify one. However, it is necessary to ensure that no one alters the public keys stored in the authentication server. Otherwise, Eve, for example, could substitute her public key for Alice’s and then could impersonate Alice. Actual implementations of server-based public key authentication systems, therefore, such as used by Novell Corporation’s NDS (Novell Directory Services), include additional security features.
Note, however, that it is not necessary to have an authentication server in order to use public key authentication. Digital certificates can take the place of a central distributor of public keys.
Certificates
The problem of ensuring that a public key actually belongs to the entity you wish to authenticate can be addressed using digital certificates. Authentication using a digital certificate is illustrated in Figure 2-11.
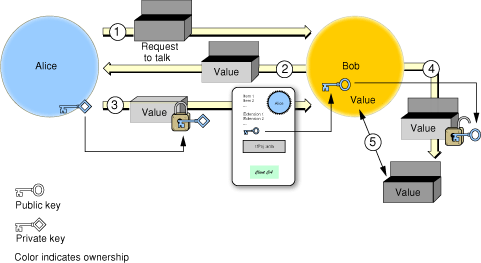
The steps are as follows:
Alice sends Bob a request to talk.
Bob generates a random value and sends it to Alice as a challenge.
Alice encrypts the value with her private key and sends it to Bob. She also sends Bob her digital certificate containing her public key.
Bob verifies the digital certificate and uses the public key to decrypt the value.
Bob compares the decrypted value to the original value, verifying that it was truly Alice who sent him the certificate.
In practice, Alice could digitally sign her response to Bob rather than separately encrypting the challenge. Certificates are described in more detail in “Digital Certificates,” and digital signatures are discussed in “Digital Signatures.”
Permissions
An important aspect of security on a computer system is the granting or denying of permissions (sometimes called access rights). A permission is the ability to perform a specific operation such as to gain access to data or to execute code. Permissions can be granted at the level of directories (folders), subdirectories, files or applications, or specific data within files or functions within applications.
Permissions in Mac OS X are controlled at many levels, from the Mach and BSD components of the kernel, through higher levels of the operating system, and—for networked applications—through the networking protocols. For iPhone OS, see “Sandboxing and the Mandatory Acccess Control Framework.”
Important: The Mach and BSD access permissions are enforced by the operating system and therefore affect every process running in Mac OS X. In contrast, application-defined security policies must be enforced by those applications. The Mac OS X security APIs discussed in this document are available for that purpose.
This section introduces the basic features of permissions at all of these levels in Mac OS X.
Mach Port Rights
At the deepest level of Mac OS X system architecture, the basis for the operating system’s built-in security features is provided by the Mach and BSD components of the kernel. This section provides only a very brief and cursory introduction to Mach. For more information on Mach in Mac OS X and Mach programming, see Kernel Programming Guide.
Note: Apple does not support Mach functions for use by external developers and does not guarantee the binary compatibility from one operating system release to the next of code that calls Mach directly. Therefore, Apple recommends against the use of Mach functions by applications. You should use higher-level APIs whenever possible, and call BSD when a low-level interface is required.
Mach security is based on ports and port rights. A Mach port is an endpoint of a communication channel between a client who requests a service and a server that provides the service. Mach ports are unidirectional; a reply to a service request must use a second port.
A port has a set of associated port rights, which are owned by tasks. A port right specifies which task can use that port. Each port has one receive right, the owner of which can receive messages on that port. Each port also has one or more send rights; the owners of the send rights can send messages to the port. Rights can be transferred between tasks by being attached to a message.
A single task (or other Mach object, such as a thread or the computer itself) may have multiple ports that provide access to resources it supports. For example, a task might have a name port and a control port. Access to the control port allows the task to be manipulated. In contrast, access to the name port merely allows the client to obtain information about the task or perform other nonprivileged operations on it.
Each process has a port right namespace, which maps small integers known as port right names to their corresponding port rights. A port right name is meaningful only within that task’s port right namespace. A task can transfer a port right to another task by sending it the corresponding port right name. However, unless it sends the name correctly, the receiving task won’t be able use the right. The only way to transmit a port right between two tasks is by sending a Mach message and attaching the right name to that message using the correct syntax and message structure.
When you use Mach to create a task, Mach returns a port right name that references a send right for the port (the receive right for a task port is always owned by the kernel). You can send messages to this port to start and stop the task, kill the task, manipulate the task’s address space, and so forth. Therefore, whoever owns a send right for a task’s port effectively owns the task and can manipulate the task’s state without regard to BSD security policies or any higher-level security policies. In other words, an expert in Mach programming with local administrator access to a Mac OS X machine can bypass BSD and higher-level security features. Therefore, it is very important to use strong administrator passwords, keep them secure, and control physical security for any computer containing sensitive information.
BSD
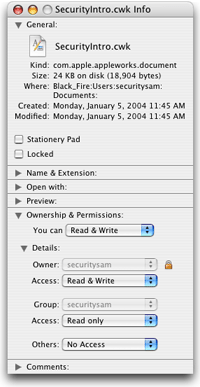
The BSD portion of the kernel is the key place within the Mac OS X operating system that enforces access to applications and files. BSD security policies are visible to users in the Finder, in the form of the Ownership and Permissions information in a file or folder’s Info dialog (Figure 2-12).
The most familiar aspect of BSD security is the file system security policy, which controls access to files and folders (directories). BSD file permissions are described in many documents, including File System Overview. In addition to the file system security policy, BSD defines two other security policies used in special cases: the owner or root security policy, and the root EUID security policy. Each of these policies is described briefly in the following subsections.
The BSD security model is based on matching up attributes of an object (such as a file) with attributes of the process attempting to gain access to that object. For example, suppose a file has an owner ID of 1234 and the file permissions specify that the owner may have read and write access to that file. Suppose further that Alice has a user ID (UID) of 1234. When Alice attempts to read the file, BSD matches her UID with the file’s owner ID and grants Alice access to read the file.
Starting in Mac OS X v10.5, the kernel includes an implementation of the TrustedBSD Mandatory Access Control (MAC) framework. Mandatory access control—also known as “sandboxing”—is discussed in “Sandboxing and the Mandatory Acccess Control Framework.”
File System Security Policy
The file system security policy is used to control access to objects in the file system, such as volumes, directories, files, symbolic links, and devices. Each file system object has a user ID (the file UID, commonly referred to as the file’s owner), a group ID (the file GID, commonly referred to as the file’s group), and three sets of permission bits, known as owner, group, and other permissions. The first set of bits controls access to the object by the owner (any process whose effective UID is equal to the file UID), the second controls access by members of the group, and the third controls access by everyone else. Each bit set contains three bits: read, write, and execute (rwx for short). The effect of these bits differs for files and directories, as shown in Table 2-1.
Bit | File | Directory |
|---|---|---|
read | Can open file for read | Can list directory contents |
write | Can open file for write | Can modify directory contents |
execute | Can treat file as a program to run | Can search the directory |
Each process has three user IDs: the real user ID (RUID), effective user ID (EUID), and saved user ID (SUID). The RUID is always inherited from the user or process that executes the process. The EUID is normally the same as the RUID, but it can differ in special circumstances as described in “Owner or Root Security Policy.” In most cases, it is the EUID that BSD checks to determine permissions. The SUID is used by BSD to enable a privileged process to switch in and out of privileged mode.
Each process also has real and saved group IDs (RGID and SGID) and up to 16 effective group IDs (EGIDs), which work in a way analogous to the process’s user IDs.
For more details on these UIDs and GIDs, see The Design and Implementation of the 4.4 BSD Operating System by Marshall McKusick and others.)
Under the file system security policy, BSD determines the permissions applicable to a process accessing a file by comparing the process’s EUID and EGIDs with the UID and GID associated with the file. If the UIDs match, BSD grants the process the permissions specified for the owner. If the UIDs do not match, BSD checks whether the process is considered a member of the group identified by the file’s GID. If it is, then BSD grants the process the permissions specified for the group. If neither of these conditions is met, the process is granted the permissions specified for “other.”
Owner or Root Security Policy
The owner-or-root security policy is used to control execution of a few specific operations. Under this policy, a specific operation on an object can be performed by any process whose EUID is the same as the object’s owner or whose EUID is 0. The user with a UID of 0 is called the root user (also called the superuser) and a process running with an EUID of 0 is said to be running asroot.
In addition to the r, w, and x bits, each file system object also has three ancillary permission bits: setuid, setgid, and sticky. Normally, when a process executes a program, the resulting process has both its RUID and EUID set to the EUID of the process that executed it. However, if the program’s setuid bit is set, it runs with the EUID equal to the program’s file UID. Therefore, if the owner of a program is the root user, the program runs with an EUID of 0. The setgid bit has a similar effect: the process runs with an EGID equal to the program file’s group UID.
The sticky bit restricts the deletion of files in a directory so that only the owner of the file, the owner of the directory, or the root user can delete a file.
A user can change the permissions only on files owned by that user. Therefore, only the root user can set the setuid bit on a program owned by root. Because such a program runs with root privileges when executed by someone other than root, it can create a security vulnerability. Therefore, it is important to restrict the creation and use of such programs.
An example of where the owner-or-root security policy applies is the chmod system call, which is used to change the permissions of a file (including the setuid and setgid bits). Only the owner of the file or a process running as root can change a file’s permissions.
Root EUID Security Policy
Under the root EUID security policy, an operation can be performed only by a process with an EUID of 0. Such operations are sometimes referred to as privileged operations. Some of the common situations where the root EUID security policy applies are:
Changing the owner of a file system object
Binding TCP/IP sockets to low-numbered ports
Making changes to the network configuration
Certain I/O Kit operations
Getting the Mach host privileged special port
Authorization Services and BSD Security Policies
Because a process running with an EUID of 0 has many special privileges, such a process can be a target of malicious hackers. To minimize such risks, you should factor your application into privileged and nonprivileged processes. See “Authorization Services” for more information and for references that describe and illustrate this technique.
Processes can change their EUID and EGID by calling setuid, setgid, and related system calls. For example, a process can run as root temporarily and then switch to a less privileged EUID to minimize exposure to malicious attacks. This technique is complicated by the confusing semantics of the setuid call and by the fact that these calls operate somewhat differently on different implementations of UNIX (including different versions of Mac OS X). For a detailed discussion of the issues involved, see Setuid Demystified by Chen, Wagner, and Dean (Proceedings of the 11th USENIX Security Symposium, 2002), available at http://www.usenix.org/publications/library/proceedings/sec02/full_papers/chen/chen.pdf. For more information on the system calls, see the man pages for setuid, setreuid, and setregid. (The setuid man page includes information about seteuid, setgid, and setegid as well.)
Sandboxing and the Mandatory Acccess Control Framework
Sandboxing provides fine-grained control of the ability of processes to access system resources. For example, you can prevent a process from connecting to any network, from writing any files, or from writing any files outside of specific directories. This feature limits the amount of damage that can be done by a malicious hacker that gains control of an application. For example, if an attacker takes control of an application that is sandboxed so that it can write files only to the folder /var/tmp, it is not possible for the hacked program to overwrite system files.
New processes inherit the sandbox restrictions of their parent.
In Mac OS X, sandboxing is provided by the Mac OS X Mandatory Access Control (MAC) framework, which is an implementation of the TrustedBSD MAC framework, documented in http://www.trustedbsd.org/mac.html.
In iPhone OS, each application is put in a sandbox that restricts the application to using only its own files and preferences, and limits the system resources to which the application has access. For example, an application can call the public networking APIs to communicate over a network, but has no direct access to the communications or networking hardware.
It’s important to note that a sandbox does not protect an application from a direct attack. For example, if you accept input from the user, don’t validate it, and there is an exploitable buffer overflow in your input-handling code, an attacker might be able to cause your program to crash or even take control of the program so that it executes the attacker’s code. The sandbox limits the damage an attacker can cause, but cannot prevent attacks.
ACLs
Starting with Mac OS X v10.4, the Mach and BSD permissions policies are supplemented by support in the kernel for ACLs (access control lists), which are data structures that provide much more detailed control over permissions than does BSD. For example, ACLs allow the system administrator to specify that a specific user can delete a file but cannot write to it. ACLs also provide compatibility with Active Directory and with the SMB/CIFS networks used by the Windows operating system. For more information on ACL support in Mac OS X for different network file systems, see “Network File Systems.”
An ACL consists of an ordered list of ACEs (access control entries), each of which associates a user or group with a set of permissions and specifies whether each permission is allowed or denied. ACEs also include attributes related to inheritance (see “Inheritance of Permissions”).
Note: File system ACLs are not related to the ACLs used by keychains, as described in Keychain Services Programming Guide.
File System Access Control Policy
You can use file system ACLs to implement more detailed and complex access control policies than are possible using only BSD permissions. They do so by using many more permission bits than the three used by BSD and by implementing both allow and deny associations for each permission for each user or group. Table 2-2 shows the permission bits used by ACLs. Compare these to the BSD permission bits shown in Table 2-1.
Bit | File | Directory |
|---|---|---|
read | Open file for read | List directory contents |
write | Open file for write | Add a file entry to the directory |
execute | Execute file | Search through the directory |
delete | Delete file | Delete directory |
append | Append to file | Add subdirectory to directory |
delete child | — | Remove a file or subdirectory entry from the directory |
read attributes | Read basic attributes | Read basic attributes |
write attributes | Write basic attributes | Write basic attributes |
read extended | Read extended (named) attributes | Read extended (named) attributes |
write extended | Write extended (named) attributes | Write extended (named) attributes |
read permissions | Read file permissions (ACL) | Read directory permissions (ACL) |
write permissions | Write file permissions (ACL) | Write directory permissions (ACL) |
take ownership | Take ownership | Take ownership |
Notice that the right to change permissions is itself controlled by a permission.
ACLs and User IDs
One of the main reasons for implementing ACLs in Mac OS X is to support network file systems such as SMB/CIFS (see “SMB/CIFS”). In order to be able to identify users and groups throughout the network, each file or directory must have universally unique identifiers (UUIDs) in addition to the locally-unique UID and GID used by BSD. Each file or directory that has associated ACLs, therefore, has four associated identities, two to support BSD and two to support ACLs:
user ID (UID)
group ID (GID)
owner UUID
group UUID
Unlike BSD, which specifies three permissions for each file (one for the file’s owner, one for members of the file’s group, and one for everyone else), an ACL can specify different permissions for each ACE. Another contrast between ACLs and BSD is that, whereas in BSD the file owner must be an individual, in the ACL permission scheme the file owner can be either a user or a group. If a file is owned by a group, its GID (used by BSD) and group UUID are always coherent (that is, there is always a simple, 1:1 mapping between them). However, because BSD does not support the concept of a group as owner of a file, in this case the system assigns a special UID that identifies the file as owned by “not a user” and the owner UUID represents a group. If the file is owned by a single individual, its UID and owner UUID are coherent.
The owner of a file using an ACL has certain unrevokable permissions (read and write permissions) regardless of the contents of the ACL. If the file is owned by an individual, the group UUID associates a group with a file system object and affects the inheritance of certain ACEs (see “Inheritance of Permissions”) but does not confer any special permissions on the group.
Evaluating Permissions
Each ACE in an ACL either allows or a denies some set of permissions. It is very important to understand that a deny ACE is not the same as the absence of an allow ACE. Rather, the system evaluates the ACEs in sequence until either all requested permissions are allowed or any requested permission is denied. A request for authorization includes a credential (which identifies the requesting entity) and the permissions required for the operation. Mac OS X v10.4 and later evaluates permissions using the following algorithm (also, see “Inheritance of Permissions” for a discussion of inherited permissions):
If the requested permissions would change the object, and the file system is read-only or the object is marked as immutable, the operation is denied.
If the entity making the request is the root user, the operation is allowed.
If the entity making the request is the object’s owner, the requestor is given Read Permissions and Write Permissions access. If that is sufficient to satisfy the request, the operation is allowed.
If the object has an ACL, the ACEs in the ACL are scanned in order. (Those with deny associations are usually placed before those with allow associations.) Each ACE is evaluated according to the following criteria until either a required permission has been denied, all required permissions have been allowed, or the end of the ACL is reached:
The ACE is checked for applicability. The ACE is not considered applicable if it does not refer to any of the requested permissions. In addition, the requesting entity must be the same as the entity named in the ACE, or the requestor must be a member of a group named in the ACE. (Groups may be nested and an external directory service may be used to resolve group membership.) Non-applicable ACEs are ignored.
If the ACE denies any of the requested permissions, then the request is denied. (Note that Read Permissions and Write Permissions are granted to the object’s owner, regardless of whether allowed or denied by ACEs.)
If the ACE allows any of the requested permissions, the system adds this permission to the list of granted permissions. If the granted permissions include all the requested permissions, the request is allowed and the process stops. If the list is not complete, the system goes on to check the next ACE.
If the end of the ACL is reached without finding all of the required permissions, and if the object also has BSD permissions, then the system checks the unsatisfied permissions against the BSD permissions. If these are sufficient to grant all required permissions, the request is allowed. If the permission requested has no BSD equivalent (such as “take ownership”), then it is considered still outstanding and the request is denied.
If the file system object has no ACL, then permissions are evaluated according to the BSD security policies, as described in “BSD.”
The credential of the requesting entity is equivalent to the effective UID (that is, the EUID) of the program attempting to open or execute a file. The EUID is normally the same as the UID of the user or process that executes the process., but it can differ in special circumstances (involving the setuid bit) as described in “Owner or Root Security Policy.”
Inheritance of Permissions
BSD permissions are assigned only on a per-file basis, so that the permissions assigned to a directory do not affect the permissions of a new file or subdirectory created in that directory. Although you can apply the permissions of a directory to enclosed items, doing so is a one-time operation. Any newly created files or subdirectories are not affected—they are created with default permissions.
With ACLs, by contrast, newly created files and subdirectories can inherit permissions from their enclosing directory. Each ACE on a directory can contain any combination of the following inheritance flags:
Inherited (this ACE was inherited).
File Inherit (this ACE should be inherited by files created within this directory.
Directory Inherit (this ACE should be inherited by directories created within this directory).
Inherit Only (this ACE should not be checked during authorization).
No Propagate Inherit (this ACE should be inherited only by direct children; that is, the ACE should lose any Directory Inherit or File Inherit bit when inherited).
When it creates a new file, the kernel goes through the entire access control list of the parent directory and copies to the file’s ACL any ACEs that are marked for file inheritance. Similarly, when it creates a new subdirectory, the kernel copies to the subdirectory’s ACL any ACEs that are marked for directory inheritance.
If a file is copied and pasted into a directory, the kernel replicates the contents of the source file into a new file at the destination. Because it is creating a new file, the system checks the ACL of the parent directory and adds any inherited ACEs to whatever ACEs were in the original file. If a file is moved into a directory, on the other hand, the original file is not replicated and no ACEs are inherited. In this case, the parent directory’s ACEs are added to the moved file only if the administrator specifically propagates ACEs from the parent directory through contained files and subdirectories. Similarly, once a file has been created, changing the ACL of the parent directory does not affect the ACL of contained files and subdirectories unless the administrator specifically propagates the change.
In BSD, applying a directory’s permissions to enclosed files and subdirectories completely replaces the permissions of the enclosed objects. With ACLs, in contrast, inherited ACEs are added to other ACEs already on the file or directory.
The order in which ACEs are placed in an ACL—and therefore the order in which they are evaluated to determine permissions—is as follows:
Explicitly specified deny associations
Explicitly specified allow associations
Inherited associations, in the same order in which they appeared in the parent
Therefore, any explicitly specified ACEs take precedence over all inherited ACEs. For more information on how ACEs are evaluated, see “Evaluating Permissions.”
Because ACEs can be inherited, administrators can control the fine-grained permissions of files created in a directory by assigning inheritable ACEs to the directory. Doing so saves the work of assigning ACEs to each file individually. In addition, because ACEs can apply to groups of users, administrators can assign permissions to groups rather than having to specify permissions for each individual. Applying access security to directories and groups rather than to files and individuals saves administrator time and gives better file system performance in many circumstances.
For application programmers, it is important to note that the automatic inheritance of permissions from directories means that it is not necessary for an application to create an ACL for each new file it creates or to maintain inherited ACEs when a file is saved, because the kernel creates the ACL for the file using inherited ACEs. (Note that assignment and inheritance of BSD permissions are not affected by ACLs. If ACLs are not supported, the BSD permissions are used. For more information on the way permissions are evaluated when both ACLs and BSD permissions are set, see “Evaluating Permissions.”)
In Mac OS X Server v10.4, the server administrator can perform the following operations:
Copy permissions from a parent directory to all files and directories below it in the hierarchy. This makes permissions uniform in the directory tree and should be used only for BSD permissions.
Propagate permissions from a parent directory to all files and directories below it in the hierarchy. In this case, explicitly specified ACEs are unchanged and ACEs inherited from them are unchanged. Files and subdirectories inherit ACEs as if they had been newly created in place under the directories that have explicitly specified ACEs, as illustrated in Figure 2-13.
Apply inheritance from a parent directory to a specific directory or file.
Make inherited ACEs in directories explicit.
Remove all ACEs from directories and files.
Enable or disable ACLs on a volume.
The server GUI cannot directly manipulate ACEs of files. There is no GUI in the Finder to set or change ACEs. ACEs can be read and set both on the server and client using the command-line tools ls and chmod.

Mac OS X
This section discusses how Mac OS X uses BSD permissions.
The Root User
The root user owns many of the primary system processes and has unlimited access to the file system objects on the devices attached to the computer. For example, the root user can:
Read, write, and execute any file
Copy, move, and rename any file or folder
Transfer ownership and reset permissions for any file
A major difference between standard BSD permission semantics and the Mac OS X implementation is that in Mac OS X the root user is disabled after system installation. In most cases, it is not necessary for an administrator to run as root (see “The Admin Group”). You may also assume root power by using the sudo utility. Although the sudo utility does not require you to enable the root user, you can use it only from the Terminal application; that is, you must have physical access to the machine to use it. See the sudo man page for more information on its use.
The root user should not be enabled on user systems. If your application needs to perform operations as the root user, you must use Authorization Services. For more information, see Authorization Services C Reference and Authorization Services Programming Guide in Security Documentation.
Note: In almost all cases you can run as a member of the admin group or use sudo rather than enabling the root user. If you absolutely must enable the root user, run the NetInfo Manager utility and authenticate yourself as the local administrator. Then choose Enable Root User from the Security menu. This menu item is enabled only if you are a member of the local admin group—a group with special administrative privileges—and you have been previously authenticated in the local domain. Once you’ve enabled the root user, the password is blank, so you should give the root user a password by selecting Change Root Password from the Security menu. After you’ve completed the task requiring root access, you should relinquish root user privileges by choosing Disable Root User from the Security menu.
Whereas most user permissions apply across networks, often the concept of a root user does not. In most cases, the root user is mapped to nobody—a special user with very little access. This prevents the root user on one computer from becoming the root user on another computer.
The Wheel Group
There is a special group in BSD called the wheel group. Membership in the wheel group confers on users the ability to become the root user by using the su utility on the command line. Users who are not in the wheel group can’t become the root user, even if they have the correct password. In Mac OS X v 10.3 and later, the wheel group is not used. Its functions have been assumed by the admin group.
The Admin Group
Mac OS X provides the admin group in place of the root user. A member of the admin group (referred to as an administrator) can perform almost all functions the root user can, and can do them using the Finder—that is, without resorting to the command line. The only thing the administrator is prevented from doing is directly adding, modifying, or deleting files in the system domain. An administrator can use special applications such as Installer or Software Update for this purpose, however.
The user who installs Mac OS X on a system becomes automatically the first administrator for the system. Thereafter, this user (or any other administrator) can use Accounts preferences to create accounts on the local system for new users and can grant administrative privileges to any user on the system.
Network File Systems
This section discusses the use of permissions by network file server protocols. Mac OS X supports four network file server protocols:
AFP—Apple Filing Protocol, the principal file-sharing protocol in Mac OS 9 systems, used by AppleShare servers and clients.
NFS—Network File System, the main file-sharing protocol used by UNIX systems.
SMB/CIFS—Server Message Block/Common Internet File System, a file-sharing protocol used on Windows and UNIX systems
WebDAV—Web-based Distributed Authoring and Versioning, an extension of HTTP that allows collaborative file management on the web.
AFP
If the AppleShare client and server both support AFP 3.0, the actual BSD permissions are transported over the connection. If the file or directory on the AFP server has an ACL, the ACL is transported over the connection and the effective permissions are displayed by the Finder. However, enforcement of permissions is done only on the server, not on the client. See “ ACLs” for more information on the Mac OS X implementation of ACLs.
If the connection is using AFP 2.x, you should be aware of the differences in how permissions work:
BSD supports permissions on files, whereas AFP 2.x does not.
BSD implements a “best match” permissions policy: if you’re the owner, you get the owner permissions; if you’re not the owner but you’re in the file’s group, you get the group permissions; otherwise, you get the other permissions. AFP implements a cumulative permissions policy: your permissions are the union of the permissions you derive from the owner, group, and other permissions. For example, if a folder is writable by the group but not by the owner, AFP permissions let the owner modify the folder but BSD permissions do not.
BSD interprets the rwx bits for folders as shown in Table 2-1. AFP permissions define them as “See Files”, “See Folders”, and “Make Changes”. When dealing with an AppleShare 2.x server, the Mac OS X AppleShare client maps between these privilege models. A similar mapping applies when you connect to a Mac OS X server using an AppleShare 2.x client.
ACLs are not supported by AFP 2.x.
AFP excludes a process having an EUID of 0 (that is, one running as root) from accessing any data over the network.
NFS
In general, NFS is not a secure protocol, because most NFS servers trust their clients. That is, if a client says that this file operation is done on behalf of user Bob, the server does the operation on behalf of user Bob. However, if you have root access on the client, you can pretend to be user Bob and access any of Bob’s files on the NFS server. To maintain some security, most NFS servers map the root user to a special user, nobody, which owns no files or directories. For this reason, if your EUID is 0 you can, in general, access only those files on an NFS server that allow access to “other”.
SMB/CIFS
SMB is a networking protocol for file sharing commonly used on Windows networks. CIFS is often used as a synonym for SMB. Samba is software that implements an SMB/CIFS server on UNIX. Therefore, this file sharing protocol is variously referred to as SMB, CIFS, SMB/CIFS, Samba, and Windows file sharing.
Mac OS X v10.4 and later implements SMB/CIFS-compatible access control lists (ACLs). Although individual users cannot set or alter ACLs, server administrators can do so. (Administrators can use the SMB server command line to manipulate ACLs, but only if both the client and server are bound to the same Active Directory domain.) However, enforcement of permissions is done only on the server, not on the client. See “ ACLs” for more information on the Mac OS X implementation of ACLs.
For Mac OS X v10.3 and earlier, all of the SMB access controls in Mac OS X are implemented on the server, not the client. Consequently, when a Mac OS X user mounts an SMB file server, the volume, directory, or file mounted appears in the Finder to allow read, write, and execute access and to be owned by the user. However, when the user attempts to open a folder or file, the server evaluates the user’s access permissions and either allows access or prompts the user for a new user name and password before granting access.
For more information on SMB/CIFS permissions and to learn how to modify their behavior, see the man page for SMB (man 5 smb.conf).
WebDAV
The WebDAV protocol is an extension to the HTTP protocol that allows users to write and edit web content remotely; that is, over a network connection. The Mac OS X WebDAV file system uses WebDAV and HTTP requests to access resources on a WebDAV-enabled HTTP server as files and directories.
The WebDAV protocol does not support users and groups. Furthermore, a WebDAV client cannot determine access permissions for files and directories on a WebDAV server before attempting to access them. Therefore, the WebDAV file system in Mac OS X sets the user and group IDs to unknown for all files and directories and the permissions default to read, write, and execute for everyone: user, group, and other.
When the WebDAV file system sends a request to a WebDAV-enabled HTTP server, the server determines whether authorization is required. If no authorization is required, the server accepts the request. If authorization is required, the server checks for authentication credentials (such as a user name and password) and, if they are present and correct, the server authorizes the client and allows access. If authorization is required and no credentials were sent or the credentials are not correct, the server rejects the request with a challenge for authentication. If the user cannot supply the correct credentials, the WebDAV file system refuses access.
For more information on the protocols used by the WebDAV file system, see the following documents:
Hypertext Transfer Protocol—HTTP/1.1http://www.ietf.org/rfc/rfc2616.txt
HTTP Authentication: Basic and Digest Access Authenticationhttp://www.ietf.org/rfc/rfc2617.txt
HTTP Extensions for Distributed Authoring—WEBDAVhttp://www.ietf.org/rfc/rfc2518.txt
Authorization
Mac OS X uses authorization to control access to files and programs. The iPhone OS uses sandboxing for this purpose (see “Sandboxing and the Mandatory Acccess Control Framework”). Before a user or service on Mac OS X can execute a program or gain access to data, it must be authorized to do so. Authorization is normally a three-step process:
Authenticate a user or service (see “Authentication and Identification Methods”).
Determine the user’s or service’s permissions (see “Permissions”).
Decide whether to give the user or service access to the data or allow them to execute the program.
The first step, authentication, may be omitted in special circumstances, such as when a user is using a ticket (see “Kerberos and Authorization.”)
Authentication and determination of permissions are facilitated by Authorization Services (see “Authorization Services”). Each individual process, whether the Finder or your application, must then make its own determination of whether to allow access to the data or code it controls. The BSD permissions structure provides a basic level of access permission. You can implement more sophisticated or fine-grained access permissions based on user access lists or security policies of your own design. For example, you can let any user run your application but allow only users who are members of the admin group to change application preferences.
Authorization Services can be used to implement such security policies. For details, see Authorization Services C Reference and Authorization Services Programming Guide in Security Documentation.
Secure Storage
Secure storage is the protection of data through either access permissions or encryption. Access permissions can prevent users who are not computer experts from gaining access to data but cannot prevent someone who is capable of bypassing the operating system from reading data off the disk or out of memory. Therefore, highly sensitive data must be stored in an encrypted form.
Mac OS X and iPhone OS provide an API, called Keychain Services, for securely storing small amounts of data, such as passwords or other short text strings. Mac OS X includes a utility that allows users to store and read the data in the keychain, called Keychain Access. In Mac OS X v10.3 and later, users can encrypt their entire Home folder by using FileVault, available through Security preferences. In Mac OS X, there is no high-level API for general encryption or for encryption of files or directories. You must use the CSSM API to perform such operations. For examples of code using CSSM for common encryption tasks, see the CryptoSample sample code. In iPhone OS, the Certificate, Key, and Trust Services API includes functions for encrypting and decrypting blocks of data.
In iPhone OS, backups of data to the user’s computer are stored in plaintext, with the exception of passwords and other secrets on the keychain, which remain encrypted in the backup. It is therefore important to use the keychain to store passwords and other data (such as cookies) that are used to access secure web sites, as otherwise this data might be compromised if an unauthorized person gains access to the backup data.
Secure Communication
One important aspect of computer security is the secure communication of data over a network. Although you can devise your own security protocols and use low-level APIs such as BSD sockets and CSSM to implement them, it is usually much more convenient to use standard protocols and higher-level APIs when they are available. Mac OS X uses the SSL and TLS protocols and provides the Secure Transport, CFNetwork, and URL Loading System APIs for secure communication. The CFNetwork API is available on iPhone OS as well.
Protocols for Secure Communication
SSL and TLS are versions of a security protocol that provides secure communication over a network. They are commonly used over TCP/IP connections such as the Internet. They use certificate-based authentication (“Digital Certificates”) to ensure that you are communicating with a valid server, they validate data to prevent tampering, and they can use public-key cryptography (“Asymmetric Keys”) to guard against eavesdropping or message forgery. SSL is built into all major browsers and web servers (the most recent versions also include TLS). Whenever you use a secure website—for example, to send your credit card number to a vendor over the Internet—and see a protocol identifier of https rather than http at the beginning of the URL, you are using SSL or TLS for communication.
Although the TLS protocol is not interoperable with SSL, the Mac OS X and iPhone OS implementation of these protocols, Secure Transport, switches to SSL 3.0 if it cannot negotiate a TLS session with the other end of the connection.
Secure Transport uses certificate management and cryptography services provided by CDSA (“CDSA”). Secure Transport has no transport-layer dependencies; it can be used with BSD sockets, Open Transport, or any other transport-layer protocol available.
For more information on the SSL standard, see http://wp.netscape.com/eng/ssl3/ and for the TLS standard, see http://www.ietf.org/html.charters/tls-charter.html.
Secure Communication APIs
There are three secure communication APIs in Mac OS X: Secure Transport, CFNetwork, and URL Loading System. The CFNetwork API is also available on iPhone OS.
Secure Transport is the Mac OS X implementation of SSL and TLS. Applications are responsible for setting up the network connection and must provide callback functions that Secure Transport calls to perform I/O operations over the network. For more information about the capabilities and use of Secure Transport, see “Secure Transport.” For complete documentation of the Secure Transport API, see Secure Transport Reference in Security Documentation.
CFNetwork is a high-level C API that makes it easy to create, send, and receive serialized HTTP messages. Because CFNetwork is built on top of Secure Transport, you can encrypt the data stream using any of a variety of SSL or TLS protocol versions.
For more information about CFNetwork, see “CFNetwork.”
URL Loading System is a higher-level Mac OS X API built on CFNetwork. Rather than creating and maintaining a connection or a data stream, URL Loading System allows you to access the contents of a specific URL, including a secure https:// URL. See “URL Loading System.”
© 2003, 2008 Apple Inc. All Rights Reserved. (Last updated: 2008-10-15)