Change Management
The collection of framework objects that mediate between the objects in your application and external data stores is referred to collectively as the “persistence stack.” At the top of the stack are managed object contexts, at the bottom of the stack are “persistent object stores.” Between managed object contexts and persistent object stores there is a persistent store coordinator.
Core Data provides a default configuration of the persistence stack that is composed of a single managed object context, a persistent store coordinator, and a single persistent object store with an external data store. In a given stack there can be only one persistent store coordinator, however you may add managed object contexts and/or persistent object stores if required. You may also create additional stacks if you require.
Contents:
Persistence Stacks
Disjoint Edits
Communicating Changes Between Contexts
Persistence Stacks
The persistent store coordinator is designed to present a façade to the managed object contexts so that a group of persistent stores appears as a single aggregate store. A managed object context can then create an object graph based on the union of all the data stores the coordinator covers. An example is illustrated in Figure 1, where employees and departments are stored in one file, and customers and companies in another. When you fetch objects they are automatically retrieved from the appropriate file, and when you save, they are archived to the appropriate file.
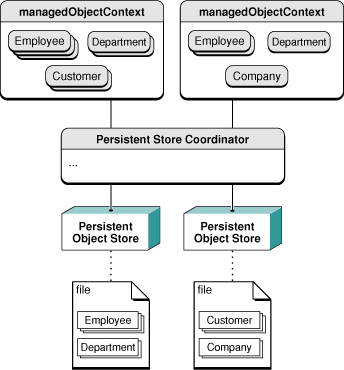
In effect, a persistent store coordinator “defines” a stack—whether you have a single application with multiple stacks, or multiple applications. For example, the image shown in Figure 2 could represent two stacks within a single application accessing the same store or two applications accessing the same store.

If you need to create a new stack, then you create a new persistent store coordinator, and add persistent stores as appropriate. You might do this to support file versioning—each coordinator (and thus managed object context) may use different copies, and hence different versions, of a managed object model.
There are no methods for you to interact directly with a persistent object store. If necessary, you can get identifiers for a coordinator’s underlying object stores. This allows you to determine, for example, whether a store has already been added, or whether two objects come from the same store.
Disjoint Edits
The object graph associated with any given managed object context must be internally consistent. If you have multiple managed object contexts in the same application, however, it is possible that may each contain objects that represent the same entries in the persistent store, but whose characteristics are mutually inconsistent. In an employee application, for example, you might have two separate windows that display the same set of employees, but distributed between different departments and with different managers, as shown in Figure 3.
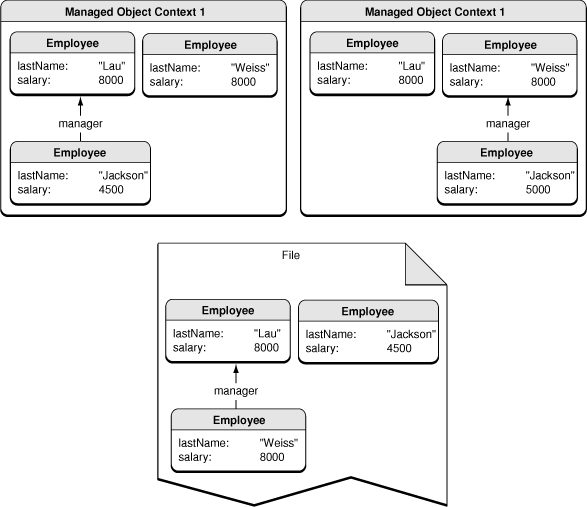
Ultimately though there can only be one “truth,” and differences between these views must be detected and reconciled when data is saved. When one of the managed object contexts is saved, its changes are pushed through the persistent store coordinator to the persistent store. When the second managed object context is saved, conflicts are detected using a mechanism called optimistic locking; how the conflicts are resolved depends on how you have configured the context.
Conflict Detection and Optimistic Locking
When Core Data fetches an object from a persistent store, it takes a snapshot of its state. A snapshot is a dictionary of an object’s persistent properties—typically all its attributes and the global IDs of any objects to which it has a to-one relationship. Snapshots participate in optimistic locking. When the framework saves, it compares the values in each edited object’s snapshot with the then-current corresponding values in the persistent store.
If the values are the same, then the store has not been changed since the object was fetched, so the save proceeds normally. As part of the save operation, the snapshots' values are updated to match the saved data.
If the values differ, then the store has been changed since the object was fetched or last saved; this represents an optimistic locking failure.
Conflict Resolution
You can get an optimistic locking failure if more than one persistence stack references the same external data store (whether you have multiple persistence stacks in a single application or you have multiple applications). In this situation there is the possibility that the same conceptual managed object will be edited in two persistence stacks simultaneously. In many cases, you want to ensure that subsequent changes made by the second stack do not overwrite changes made by the first, but there are other behaviors that may be appropriate. You can choose the behavior by choosing for the managed object context a merge policy that is suitable for your situation.
The default behavior is defined by the NSErrorMergePolicy. This policy causes a save to fail if there are any merge conflicts. In the case of failure, the save method returns with an error with a userInfo dictionary that contains the key @"conflictList"; the corresponding value is an array of conflict records. You can use the array to tell the user what differences there are between the values they are trying to save and those current in the store. Before you can save you must either fix the conflicts (by re-fetching objects so that the snapshots are updated) or choose a different policy. The NSErrorMergePolicy is the only policy that generates an error. Other policies—NSMergeByPropertyStoreTrumpMergePolicy, NSMergeByPropertyObjectTrumpMergePolicy, and NSOverwriteMergePolicy—allow the save to proceed by merging the state of the edited objects with the state of the objects in the store in different ways. The NSRollbackMergePolicy discards in-memory state changes for objects in conflict and uses the persistent store’s version of the objects’ state.
Snapshot Management
An application that fetches hundreds of rows of data can build up a large cache of snapshots. Theoretically, if enough fetches are performed, a Core Data-based application can contain all the contents of a store in memory. Clearly, snapshots must be managed in order to prevent this situation.
Responsibility for cleaning up snapshots rests with a mechanism called snapshot reference counting. This mechanism keeps track of the managed objects that are associated with a particular snapshot—that is, managed objects that contain data from a particular snapshot. When there are no remaining managed object instances associated with a particular snapshot (which Core Data determines by maintaining a list of these references), that snapshot is released.
Communicating Changes Between Contexts
If you use more than one managed object context in an application, Core Data does not automatically notify one context of changes made to objects in another. In general, this is because a context is intended to provide a scratch pad where you can make changes to objects in isolation, and if you wish you can discard the changes without affecting other contexts. If you do need to synchronize changes between contexts, how a change should be handled depends on the user visible semantics you want in the second context, and on the state of the objects in the second context.
Consider an application with two managed object contexts and a single persistent store coordinator. If a user deletes an object in the first context (moc1), you may need to inform the second context (moc2) that has been deleted. In all cases, moc1 posts an NSManagedObjectContextDidSave notification that your application should register for and use as the trigger for whatever actions it needs to take. This notification contains information not only about deleted objects, but also about changed objects. You need to handle these changes since they may be the result of the delete (most of the ways this can happen involve transient relationships or fetched properties).
There are multiple axes you must consider when deciding how you want to handle your delete notification. The important ones are:
What other changes exist in the second context?
Does the instance of the object that was deleted have changes in the second context?
Can the changes made in the second context be undone?
These are somewhat orthogonal, and what actions you take to synchronize the contexts depend on the semantics of your application. The following three strategies are presented in order of increasing complexity.
The simplest case is when the object itself has not changed in
moc2and you do not have to worry about undo; in this situation, you can just delete the object. The next timemoc2saves, the framework will notice that you are trying to re-delete an object, ignore the optimistic locking warning, and continue without error.If you do not care about the contents of
moc2, you can simply reset it (usingreset) and refetch any data you need after the reset. This will reset the undo stack as well, and the deleted object is now gone. The only issue here is determining what data to refetch. You can do this by, before you reset, collecting the IDs (objectID) of the managed objects you still need and using those to reload once the reset has happened (you must exclude the deleted IDs, and it is best to create fetch requests withINpredicates to avoid problems will not being able to fulfill faults for deleted IDs).If the object has changed in
moc2, but you do not care about undo, your strategy depends on what it means for the semantics of your application. If the object that was deleted inmoc1has changes inmoc2, should it be deleted frommoc2as well? Or should it be resurrected and the changes saved? What happens if the original deletion triggered a cascade delete for objects that have not been faulted intomoc2? What if the object was deleted as part of a cascade delete?There are two workable options (a third, unsatisfactory option is described later):
The simplest strategy is to just discard the changes by deleting the object.
Alternatively, if the object is standalone, you can set the merge policy on the context to
NSMergePolicyOverwrite. This will cause the changes in the second context to overwrite the delete in the database.Note that this will cause all changes in
moc2to overwrite any changes made inmoc1.
The preceding are the best solutions, and are least likely to leave your object graph in an unsustainable state as a result of something you missed. There are various other strategies, but all are likely to lead to inconsistencies and errors. They are listed here as examples so that you can recognize them and avoid them. If you find yourself trying to adopt any of these strategies, you should redesign your application's architecture to follow one of the patterns described previously.
If you have a situation like 3(b) above, but the object not standalone, and for some reason you want to save those changes, the best you're likely to be able to do is to resurrect the part of the graph that had been loaded into
moc2, which may or may not make sense in the context of your application. Again you do this by setting the merge policy toNSMergePolicyOverwrite, but you also need some up-front application design, and some meddling with the objects in the 'deleted' object's relationships.In order for the world to make some amount of sense later, you need to automatically fault in any relationships that might need to be resurrected when you fault in the object. Then, when you get a delete notification, you need to make the context think all the objects related to the deleted object have changed, so that they will be saved as well. This will bloat your application's memory use, since you'll end up with possibly irrelevant data as a precaution against something that may not happen, and if you're not careful, you can end up with your database in a hybrid state where it is neither what
moc1tried to create, nor whatmoc2would expect (for example, if you missed a relationship somewhere and you now have partial relationships, or orphaned nodes).The second worst of all worlds is when you have changes to other objects you can't blow away in the second MOC, the object itself has changes that you are willing to discard, and you care about undo. You can't reset the context, because that loses the changes. If you delete the object, the delete will get pushed onto the undo stack and will be undoable, so the user could undo, resave, and run into the semantic problems mentioned in 3 above, only worse because you have not planned for them.
The only real way to solve this is to—separately, in your application code—keep track of the objects which are changed as a result of the delete. You then need to track user undo events, and when the user undoes past a delete, you can then "rerun" the deletion. This is likely to be complex and inefficient if a significant number of changes are propagated.
The worst case is you have changes to other objects you cannot discard, the object has changes you want to keep, and you care about undo. There may be a way to deal with this, but it will require considerable effort and any solution is likely to be complicated and fragile.
© 2004, 2009 Apple Inc. All Rights Reserved. (Last updated: 2009-03-04)