Faulting and Uniquing
Core Data uses two features to ensure that the object graph is no larger than is necessary and that a given instance of an entity is not represented more than once in a given managed object context. These features are known as faulting and uniquing respectively.
Contents:
Faulting
Consider an application that allows a user to fetch and edit details about a single employee. The application requires in memory only an object that represents that employee. The employee, however, has a relationship to a manager and to a department. These objects in turn have other relationships. If it were a requirement that the object graph be complete, then in order to edit a single attribute of a single employee it would be necessary to create objects to represent the whole corporate structure. Core Data avoids this situation by using a technique known as faulting.
Important: Only a managed object, or the collection that represents a to-many relationship, can be a fault. There is no way to load individual properties of a managed object. For patterns to deal with large attributes, see “Large Data Objects (BLOBs).”
Core Data faults are analogous to virtual memory page faults—they are simply scoped to objects instead of memory pages. The malloc and calloc functions do not guarantee whether the memory they "allocate" for you actually exists—until you actually use it. Even if you do get a pre-existing page from malloc, it may not be in physical memory. In an analogous way, in Core Data a fault is a placeholder object that represents an object that has not yet been fully realized or a collection of objects in a relationship. (To-many relationships have two levels of faulting. The first is for a collection—the set—that represents the contents of the relationship by identity. The second is for the faulting of the individual destination objects.) It is an instance of the class appropriate to the relationship’s destination, but its persistent variables are not yet initialized.
Fault handling is transparent. If at some stage a persistent property of a fault object is accessed, then Core Data automatically retrieves the data for the object and initializes the object (see NSManagedObject for a list of methods that do not cause faults to fire). This process is commonly referred to as firing the fault.
Note: Core Data avoids the term "unfaulting" because it is confusing. There's no "unfaulting" a virtual memory page fault. Page faults are triggered, caused, fired, or encountered. Of course, you can release memory back to the kernel in a variety of ways (using the functions vm_deallocate, munmap, or sbrk). Core Data describes this as "turning an object into a fault".
Consider the following example. When an application launches you retrieve a single Employee object from a persistent store. Initially its manager, department, and reports relationships are represented by faults. Figure 1 shows an employee’s department relationship represented by a fault. Although the fault is an instance of the Department class, it has not yet been realized—none of its persistent instance variables have yet been set. If you send the Department object a message to get, say, its name, then the fault fires—and in this situation Core Data executes a fetch for you to retrieve all the object's attributes.
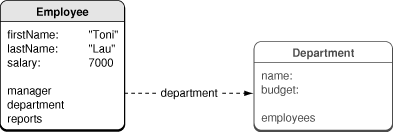
Firing Faults
There should typically be no need to fire a fault yourself. Core Data automatically fires faults when necessary (when a persistent property of a fault is accessed). Moreover, firing faults individually can be inefficient, and there are better strategies for getting data from the persistent store (see “Batch Faulting and Pre-fetching with the SQLite Store”). If you find that you need to, however, you can explicitly fire a fault by sending an object a willAccessValueForKey: message, passing nil as the argument.
For more about how to efficiently deal with faults and relationships, see “Fetching Managed Objects.”
Turning Objects Into Faults
There are good reasons for turning a realized object into a fault, which you can do using refreshObject:mergeChanges: (typically passing NO as the mergeChanges argument). Turning a managed object into a fault releases unnecessary memory, sets its in-memory property values to nil, and releases any retains on related objects. This can be useful in pruning the object graph (see “Reducing Memory Overhead”), as well as ensuring property values are current (see “Ensuring Data Is Up-to-Date”). When an object turns into a fault, it is sent a didTurnIntoFault message. You may implement a custom didTurnIntoFault method to perform various "housekeeping" functions (see, for example, “Ensuring Data Is Up-to-Date”).
Realizing a Managed Object
It is important to understand the different ways in which a managed object is realized.
If you execute a fetch using
executeFetchRequest:error:, this always results in a round trip to the persistent store to fetch the data. The objects returned in the results array are fully realized, and their data is stored in a cache (held by the persistent store coordinator).If you fire a fault, Core Data does not go back to the store if the data is available in the cache. With a cache hit, converting a fault into a realized managed object is very fast—it is basically the same as normal instantiation of a managed object. If the data is not available in the cache, Core Data automatically executes a fetch for the fault object; this results in a round trip to the persistent store to fetch the data, and again the data is cached in memory.
The corollary of the second point is that whether an object is a fault is not the same as whether its data has been retrieved from the store. Whether or not an object is a fault simply means whether or not a given managed object has all its attributes populated and is ready to use. If you need to determine whether or not an object is a fault, you can send it an isFault message without firing the fault. If isFault returns NO, then the data must be in memory. However, if isFault returns YES, it does not imply that the data is not in memory. The data may be in memory, or it may not, depending on many factors influencing caching.
Faults and KVO Notifications
When Core Data faults in an object, key-value observing (KVO) change notifications (see Key-Value Observing Programming Guide) are sent for the object’s properties. If you are observing properties of an object that is turned into a fault and the fault is subsequently realized, you therefore receive change notifications for properties whose values have not in fact changed.
While the values are not changing semantically from your perspective, the literal bytes in memory are changing as the object is materialized. The key-value observing mechanism requires Core Data to issue the notification whenever the values change as considered from the perspective of pointer comparison. KVO needs these notifications to track changes across keypaths and dependent objects.
Uniquing
In some circumstances you may fetch the same data in different ways in different parts of an application. (This is less likely to be a problem when you manage the object graph yourself and the whole graph is in memory at the same time—you either have an explicit reference to a given object or traverse relationships to reach an object.)
For example, consider the hypothetical situation illustrated in Figure 2; two employees have been fetched into a single managed object context. Each has a relationship to a department, but the department is currently represented by a fault.
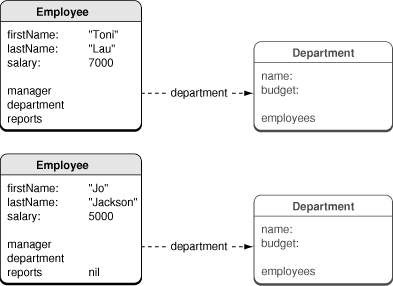
It would appear that each employee has a separate department, and if you asked each employee for their department in turn—turning the faults into regular objects—you would have two separate Department objects in memory. However, if both employees belong to the same department (for example, "Marketing"), then Core Data ensures that (in a given managed object context) only one object representing the Marketing department is ever created. If both employees belong to the same department, their department relationships would both therefore reference the same fault, as illustrated in Figure 3.
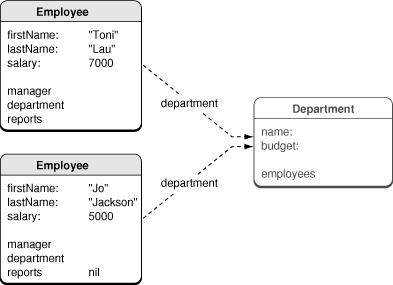
More generally, all the managed objects in a given context that refer to the Marketing Department object refer to the same instance—they have a single view of Marketing’s data—even if it is a fault. The mechanism by which Core Data ensures that—in a given managed object context—an entry in a persistent store is associated with only one managed object is known as uniquing.
If Core Data did not use uniquing, then if you fetched all the employees and asked each in turn for their department—thereby firing the corresponding faults—a new Department object would be created every time. This would result in a number of objects, each representing the same department, that could contain different and conflicting data. When the context was saved, it would be impossible to determine which is the correct data to commit to the store.
It is important to note that the discussion has focused on a single managed object context. Each managed object context represents a different view of the data. If the same employees are fetched into a second context, then they—and the corresponding Department object—are all represented by different objects in memory. The objects in different contexts may have different and conflicting data. It is precisely the role of the Core Data architecture to detect and resolve these conflicts at save time.
© 2004, 2009 Apple Inc. All Rights Reserved. (Last updated: 2009-03-04)