Relationships and Fetched Properties
There are a number of things you have to decide when you create a relationship. What is the destination entity? Is it a to-one or a to-many? Is it optional? If it’s a to-many, are there maximum or minimum numbers of objects that can be in the relationship? What should happen when the source object is deleted? You can provide answers to all these in the model. One of the particularly interesting cases is a many-to-many relationship; there are two ways to model these, and which one you choose will depend on the semantics of your schema.
When you modify an object graph, it is important to maintain referential integrity. Core Data makes it easy for you to alter relationships between managed objects without causing referential integrity errors. Much of this behavior derives from the relationship descriptions specified in the managed object model.
Core Data does not let you create relationships that cross stores. If you need to create a relationship from objects in one store to objects in another, you should consider using fetched properties.
Contents:
Relationship Definitions in the Model
Manipulating Relationships and Object Graph Integrity
Many-to-Many Relationships
Unidirectional Relationships
Cross-Store Relationships
Fetched Properties
Relationship Definitions in the Model
Creating a relationship in a managed object model is straightforward, but there are a number of aspects of a relationship that you need to specify properly. The most immediately obvious features are the relationship's name, the destination entity, and the cardinality (is it a to-one relationship, or a to-many relationship). The most important features with respect to object graph integrity, however, are the inverse relationship and the delete rule. The validity of the graph is affected by the settings for optionality and for maximum and minimum count.
Relationship Fundamentals
A relationship specifies the entity, or the parent entity, of the objects at the destination. This can be the same as the entity at the source (a reflexive relationship). Relationships do not have to be homogeneous. If the Employee entity has two sub-entities, say Manager and Flunky, then a given department's employees may be made up of Employees (assuming Employee is not an abstract entity), Managers, Flunkies, or any combination thereof.
You can specify a relationship as being to-one or to-many. To-one relationships are represented by a reference to the destination object. To-many relationships are represented by mutable sets (although fetched properties are represented by arrays). Implicitly, “to-one” and “to-many” typically refer to “one-to-one” and “one-to-many” relationships respectively. A many-to-many relationship is one where a relationship and its inverse are both to-many. These present some additional considerations, and are discussed in greater detail in “Many-to-Many Relationships.”
You can also put upper and lower limits on the number of objects at the destination of a to-many relationship. The lower limit does not have to be zero. You can if you want specify that the number of employees in a department must lie between 3 and 40. You also specify a relationship as either optional or not optional. If a relationship is not optional, then in order to be valid there must be an object or objects at the destination of the relationship.
Cardinality and optionality are orthogonal properties of a relationship. You can specify that a relationship is optional, even if you have specified upper and/or lower bounds. This means that there do not have to be any objects at the destination, but if there are then the number of objects must lie within the bounds specified.
It is important to note that simply defining a relationship does not cause a destination object to be created when a new source object is created. In this respect, defining a relationship is akin to declaring an instance variable in a standard Objective-C class. Consider the following example.
@interface Widget : NSObject |
{ |
Sprocket *sprocket; |
} |
If you create an instance of Widget, an instance of Sprocket is not created unless you write code to cause it to happen (for example, by overriding the init method). Similarly, if you define an Address entity, and a non-optional to-one relationship from Employee to Address, then simply creating an instance of Employee does not create a new Address instance. Likewise, if you define a non-optional to-many relationship from Employee to Address with a minimum count of 1, then simply creating an instance of Employee does not create a new Address instance.
Inverse Relationships
Most relationships are inherently bi-directional. If a Department has a to-many relationship to the Employees that work in a Department, there is an inverse relationship from an Employee to the Department. The major exception is a fetched property, which represents a weak one-way relationship—there is no relationship from the destination to the source (see “Fetched Properties”).
You should typically model relationships in both directions, and specify the inverse relationships appropriately. Core Data uses this information to ensure the consistency of the object graph if a change is made (see “Manipulating Relationships and Object Graph Integrity”). For a discussion of some of the reasons why you might want to not model a relationship in both directions, and some of the problems that might arise if you don’t, see “Unidirectional Relationships.”
Relationship Delete Rules
A relationship's delete rule specifies what should happen if an attempt is made to delete the source object. Note the phrasing in the previous sentence—"if an attempt is made…". If a relationship's delete rule is set to Deny, it is possible that the source object will not be deleted. Consider again a department's employees relationship, and the effect that the different delete rules have.
If there is at least one object at the relationship destination, then the source object cannot be deleted.
For example, if you want to remove a department, you must ensure that all the employees in that department are first transferred elsewhere (or fired!) otherwise the department cannot be deleted.
Set the inverse relationship for objects at the destination to null.
For example, if you delete a department, set the department for all the current members to null. This only makes sense if the department relationship for an employee is optional, or if you ensure that you set a new department for each of the employees before the next save operation.
Delete the objects at the destination of the relationship.
For example, if you delete a department, fire all the employees in that department at the same time.
Do nothing to the object at the destination of the relationship.
For example, if you delete a department, leave all the employees as they are, even if they still believe they belong to that department.
- Deny
- Nullify
- Cascade
- No Action
It should be clear that the first three of these rules are useful in different circumstances. For any given relationship it is up to you to choose which is most appropriate, depending on the business logic. It is less obvious why the No Action rule might be of use, since if you use it you have the possibility of leaving the object graph in an inconsistent state (employees having a relationship to a deleted department).
If you use the No Action rule, it is up to you to ensure that the consistency of the object graph is maintained. You are responsible for setting any inverse relationship to a meaningful value. This may be of benefit in a situation where you have a to-many relationship and there may be a large number of objects at the destination.
Manipulating Relationships and Object Graph Integrity
In general, programmatically manipulating relationships is straightforward. For examples of how to manipulate relationships programmatically, see “Accessing and Modifying Properties”
Since Core Data takes care of the object graph consistency maintenance for you, you only need to change one end of a relationship and all other aspects are managed for you. This applies to to-one, to-many, and many-to-many relationships. Consider the following examples.
An employee’s relationship to a manager implies a reverse relationship between a manager and the manager’s employees. If a new employee is assigned to a particular manager, it is important that the manager be made aware of this responsibility. The new employee must be added to the manager’s list of reports. Similarly, if an employee is transferred from one department to another, a number of modifications must be made, as illustrated in Figure 1. The employee’s new department is set, the employee is removed from the previous department’s list of employees, and the employee is added to the new department’s list of employees.
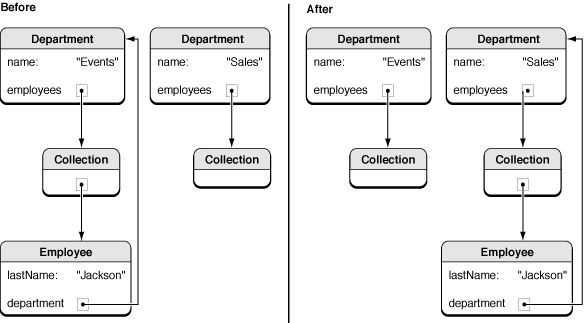
Without the Core Data framework, you must write several lines of code to ensure that the consistency of the object graph is maintained. Moreover you must be familiar with the implementation of the Department class to know whether or not the inverse relationship should be set (this may change as the application evolves). Using the Core Data framework, all this can be accomplished with a single line of code:
anEmployee.department = newDepartment; |
By reference to the managed object model, the framework automatically determines from the current state of the object graph which relationships must be established and which must be broken.
Many-to-Many Relationships
You define a many-to-many relationship using two to-many relationships. The first to-many relationship goes from the first entity to the second entity. The second to-many relationship goes from the second entity to the first entity. You then set each to be the inverse of the other. (If you have a background in database management and this causes you concern, don't worry: if you use a SQLite store, Core Data automatically creates the intermediate join table for you.)
Important: You must define many-to-many relationships in both directions—that is, you must specify two relationships, each being the inverse of the other. You can’t just define a to-many relationship in one direction and try to use it as a many-to-many. If you do, you will end up with referential integrity problems.
This works even for relationships back to the same entity (often called “reflexive” relationships). For example, if an employee may have more than one manager (and a manager can have more than one direct report), then you can define a to-many relationship directReports from Employee to itself that is the inverse of another to-many relationship, employees, again from Employee to itself. This is illustrated in Figure 2.
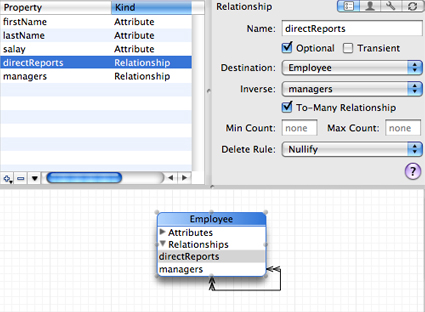
A relationship can also be the inverse of itself. For example, a Person entity may have a cousins relationship that is the inverse of itself.
Important: On Mac OS X v10.4, many-to-many relationships do not work with SQLite stores if the relationship is an inverse of itself (such as is the case with cousins).
You should also consider, though, the semantics of the relationship and how it should be modeled. A common example of a relationship that is initially modeled as a many-to-many relationship that’s the inverse of itself is “friends”. Although it’s the case that you are your cousin’s cousin whether they like it or not, it’s not necessarily the case that you are your friend’s friend. For this sort of relationship, you should use an intermediate (“join”) entity. An advantage of the intermediate entity is that you can also use it to add more information to the relationship—for example a “FriendInfo” entity might include some indication of the strength of the friendship with a “ranking” attribute. This is illustrated in Figure 3
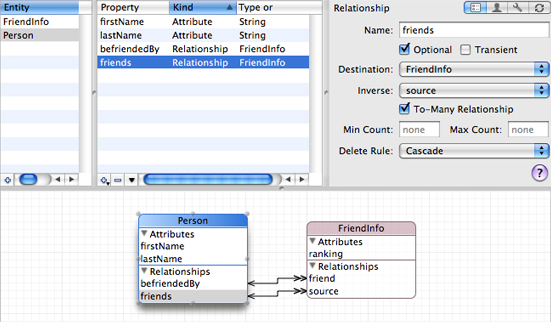
In this example, Person has two to-many relationships to FriendInfo: friends represents the source person’s friends, and befriendedBy represents those who count the source as their friend. FriendInfo represents information about one friendship, “in one direction.” A given instance notes who the source is, and one person they consider to be their friend. If the feeling is mutual, then there will be a corresponding instance where source and friend are swapped. There are several other considerations when dealing with this sort of model:
To establish a friendship from one person to another, you have to create an instance of FriendInfo. If both people like each other, you have to create two instances of FriendInfo.
To break a friendship, you must delete the appropriate instance of FriendInfo.
The delete rule from Person to FriendInfo should be cascade. If a person is removed from the store, then the FriendInfo instance becomes invalid, so must also be removed.
As a corollary, the relationships from FriendInfo to Person must not be optional—an instance of FriendInfo is invalid if the
sourceorfriendis null.To find out who one person’s friends are, you have to aggregate all the
frienddestinations of thefriendsrelationship, for example:NSSet *personsFriends = [aPerson valueForKeyPath:@"friends.friend"];
Conversely, to find out who consider a given person to be their friends, you have to aggregate all the
sourcedestinations of thebefriendedByrelationship, for example:NSSet *befriendedByPerson = [aPerson valueForKeyPath:@"befriendedBy.source"];
Unidirectional Relationships
It is not strictly necessary to model a relationship in both directions. In some cases it may be useful not to, for example when a to-many relationship may have a very large number of destination objects and you are rarely likely to traverse the relationship (you may want to ensure that you do not unnecessarily fault in a large number of objects at the destination of a relationship). Not modeling a relationship in both directions, however, imposes on you a great number of responsibilities, to ensure the consistency of the object graph, for change tracking, and for undo management. For this reason, the practice is strongly discouraged. It typically only makes sense to model a to-one relationship in one direction.
If you create a model with unidirectional relationships (relationships where you have specified no inverse), your object graph may end up in an inconsistent state.
The following example illustrates a situation where only modeling a relationship in one directions might cause problems. Consider a model in which you have two entities, Employee and Department, with a to-one relationship, "department", from Employee to Department. The relationship is non-optional and has a "deny" delete rule. The relationship does not have an inverse. Now consider the following code sample:
Employee *employee; |
Department *department; |
// assume entity instances correctly instantiated |
[employee setDepartment:department]; |
[managedObjectContext deleteObject:department]; |
BOOL saved = [managedObjectContext save:&error]; |
The save succeeds (despite the fact that the relationship is non-optional) as long as employee is not changed in any other way. Because there is no inverse for the Employee.department relationship, employee is not marked as changed when department is deleted (and therefore employee is not validated for saving).
If you then add the following line of code:
id x = [employee department]; |
x will be a fault to "nowhere" rather than nil.
If, on the other hand, the "department" relationship has an inverse (and the delete rule is not No Action), everything behaves "as expected" since employee is marked as changed during delete propagation.
This illustrates why, in general, you should avoid using unidirectional relationships. Bidirectional relationships provide the framework with additional information with which to better maintain the object graph. If you do want to use unidirectional relationships, you need to do some of this maintenance yourself. In the case above, this would mean that after this line of code:
[managedObjectContext deleteObject:department]; |
you should write:
[employee setValue:nil forKey:@"department"] |
The subsequent save will now (correctly) fail because of the non-optional rule for the relationship.
Cross-Store Relationships
You must be careful not to create relationships from instances in one persistent store to instances in another persistent store, as this is not supported by Core Data. If you need to create a relationship between entities in different stores, you typically use fetched properties (see “Fetched Properties”).
Fetched Properties
Fetched properties represent weak, one-way relationships. In the employees and departments domain, a fetched property of a department might be "recent hires" (employees do not have an inverse to the recent hires relationship). In general, fetched properties are best suited to modeling cross-store relationships, "loosely coupled" relationships, and similar transient groupings.
A fetched property is like a relationship, but it differs in several important ways:
Rather than being a "direct" relationship, a fetched property's value is calculated using a fetch request. (The fetch request typically uses a predicate to constrain the result.)
A fetched property is represented by an array, not a set. The fetch request associated with the property can have a sort ordering, and thus the fetched property may be ordered.
A fetched property is evaluated lazily, and is subsequently cached.
In some respects you can think of a fetched property as being similar to a smart playlist, but with the important constraint that it is not dynamic. If objects in the destination entity are changed, you must reevaluate the fetched property to ensure it is up-to-date. You use refreshObject:mergeChanges: to manually refresh the properties—this causes the fetch request associated with this property to be executed again when the object fault is next fired.
There are two special variables you can use in the predicate of a fetched property—$FETCH_SOURCE and $FETCHED_PROPERTY. The source refers to the specific managed object that has this property, and you can create key-paths that originate with this, for example university.name LIKE [c] $FETCH_SOURCE.searchTerm. The $FETCHED_PROPERTY is the entity's fetched property description. The property description has a userInfo dictionary that you can populate with whatever key-value pairs you want. You can therefore change some expressions within a fetched property's predicate or (via key-paths) any object to which that object is related.
To understand how the variables work, consider a fetched property with a destination entity Author and a predicate of the form, (university.name LIKE [c] $FETCH_SOURCE.searchTerm) AND (favoriteColor LIKE [c] $FETCHED_PROPERTY.userInfo.color). If the source object had an attribute searchTerm equal to "Cambridge", and the fetched property had a user info dictionary with a key "color" and value "Green", then the resulting predicate would be (university.name LIKE [c] "Cambridge") AND (favoriteColor LIKE [c] "Green"). This would match any Authors at Cambridge whose favorite color is green. If you changed the value of searchTerm in the source object to, say, "Durham", then the predicate would be (university.name LIKE [c] "Durham") AND (favoriteColor LIKE [c] "Green").
The most significant constraint is that you cannot use substitutions to change the structure of the predicate—for example you cannot change a LIKE predicate to a compound predicate, nor can you change the operator (in this example, LIKE [c]). Moreover, on Mac OS X version 10.4, this only works with the XML and Binary stores as the SQLite store will not generate the appropriate SQL.
© 2004, 2009 Apple Inc. All Rights Reserved. (Last updated: 2009-03-04)