Time Profiling
The first and most frequently used Shark configuration is the Time Profile. This produces a statistical sampling of the program’s or system’s execution by recording a new sample every time that a timer interrupt occurs, at a user-specified frequency (1 KHz, for 1ms sampling intervals, by default). At each interrupt, Shark records a few key facts about the state of each processor for later analysis: the process and thread ID of the executing process, the program counter, and the callstack of the routine that was executing. From this sampled information, Shark reconstructs exactly what code from which functions was executing as samples were taken.
In this section:
Statistical Sampling
Taking a Time Profile
Profile Browser
Chart View
Code Browser
Tips and Tricks
Example: Optimizing MPEG-2 using Time Profiles
Statistical Sampling
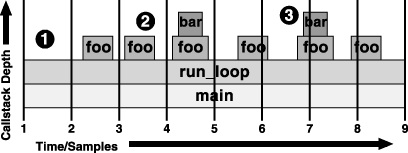
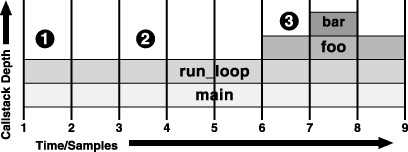
This sampling process provides an approximate view of what is executing on the system. Figure 2-1 shows the worst case of an application with a sample interval greater than the lifespan of typical function calls, while Figure 2-2 shows the corresponding statistical sample, after post processing. In the first interval (marked #1), sampling correctly identifies long-running routines executing in the sample interval. However, when encountering short functions, two effects are seen because execution time is attributed to functions only at the granularity of the sampling rate:
As seen in the third sample (marked #2), short-lived function calls can be missed entirely, so they are underrepresented in the samples.
In contrast, when brief functions occur right on the sample points, as illustrated in the seventh sample (marked #3), they are recorded as taking an entire time quantum and hence overrepresented in the samples.
Luckily, over a large number of samples these errors average out in most cases, producing a collection of samples that fairly accurately represent the actual time spent executing each function in the application. In the example from Figure 2-1 and Figure 2-2, the rare occasions when the small subroutine bar() is measured as taking an entire time quantum balances out the numerous times that it is missed entirely, providing a fairly accurate measurement of the time spent executing the routine overall. As a result, execution time measurements for the most critical routines, where the program spends most of its time executing, are generally very good.
In exchange for this inevitable measurement error, statistical sampling incurs very little overhead as it takes measurements, typically less than 2% with default settings. A major problem with performance-measuring tools is that the tool often affects the very performance it attempts to measure. The profiling tool requires a certain amount of processor time, system RAM, cache memory footprint, and other limited system resources in order to function. Inevitably, “stealing” these resources from the measured process adds artificial overhead to the program under test, sometimes skewing the performance measurements.
Statistical sampling minimizes this impact in two key ways. First, samples are taken at a relatively low frequency when compared with most event-monitoring mechanisms. The sampling mechanism's low intervention rate consumes only a small amount of processor time and memory, thereby minimizing the risk of skewed results. Second, and more subtly, samples can occur anytime during the execution of the program; side effects of the sampling mechanism are spread out to affect most areas of measured execution more or less equally. In contrast, most event counting-based mechanisms, such as function or basic block counting, record data at preset code locations, and therefore distort performance more near the preset sample points than elsewhere.
Statistical sampling provides helpful information about what executes most frequently, down to the level of individual assembly-language instructions, without the additional overhead required for an event-based profile at the instruction level. After sampling has ended, Shark correlates samples with the original binary to determine which assembly-language instructions or lines of original source code were executing when each interrupt occurred. Shark then accumulates results across samples, determining which individual lines of code were executing most often. In contrast, the overhead from adding the necessary code to profile at this level of detail in a non-statistical way would distort the results enough to render them virtually useless.
Taking a Time Profile
Recording a Time Profile is generally very simple. Just use the general session-capture instructions presented in the previous chapter with the Time Profile configuration selected, and you will capture one. Because Time Profile is usually the default configuration, recording a session can be a matter of just starting Shark and pressing the “Start” button. Using the process selection menu, you may choose between capturing samples from just one process, or of the entire system at once. The former mode is usually better for analyzing most standalone applications, while the latter is better for seeing how applications interact.
If you need more control over the sampling behavior, the mini-configuration editor (Figure 2-3) contains the most common options. The list is reasonably short:
Windowed Time Facility— If enabled, Shark will collect samples until you explicitly stop it. However, it will only store the last N samples, where N is the number entered into the sample history field (10,000 by default). This mode is also described in “Windowed Time Facility (WTF).”
Start Delay— Amount of time to wait after the user selects “Start” before data collection actually begins. This helps prevent Shark from sampling itself after you press “Start.”
Sample Interval— Enter a sampling period here to determine the sampling rate. The interval is 1 ms by default.
Time Limit— The maximum amount of time to record samples. This is ignored if WTF mode is enabled or if the sampling rate is high enough that the Sample Limit is reached first.
Sample Limit — The maximum number of samples to record. Specifying a maximum of N samples will result in at most N samples being taken, even on a multi-processor system, so this should be scaled up as larger systems are sampled. When the sample limit is reached, data collection automatically stops. With the Windowed Time Facility mode, its sample history field replaces this one, and if the Time Limit is very small it may be reached first.

Note on short sample intervals: Shark will let you decrease the sample interval significantly, to a minimum of 20µs, but the very high sampling rates that result from these very short intervals are not recommended for most work, for several reasons. First, Shark will have a significant impact on system performance, since it needs some processor time when every sample is taken. Second, sample interval timing may be more erratic, because the inevitable sample timing error caused by interrupt response timing will be a larger percentage of each sample time. Finally, Shark may require significant amounts of memory to record the large number of samples that can quickly accumulate with short-interval sampling, adding significant memory pressure on systems with smaller amounts of main memory.
Profile Browser
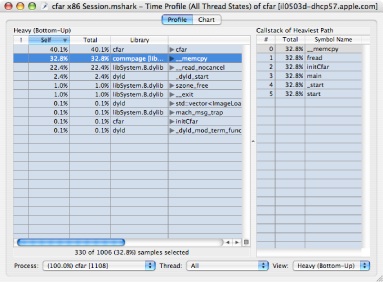
After you record a Time Profile session, Shark displays the a summary of the samples from the dominant process in a tabular form called a Profile Browser. An example is shown in Figure 2-6. Samples are grouped (usually by symbol), and the groups with the most samples are listed first. This ordering is known as the “Heavy” view, and is described further below in “Heavy View.” This view can be modified using the View popup menu (#8), if you would rather see the “Tree” view, which is described in “Tree View” and organizes the sample groups according to the program’s callgraph tree, or “Heavy and Tree” view, which splits the window and shows both simultaneously.
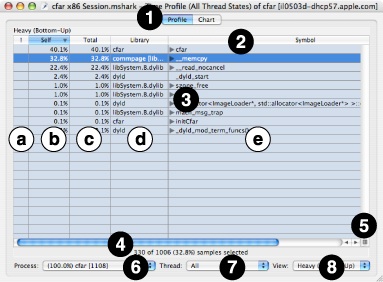
The window consists of several main parts:
Pane Tabs— These tabs let you select to view your samples using this pane, the Chart view (see “Chart View ”), or from among one or more Code Browsers (see “Code Browser”).
Results Table Column Headers— Click on any column title to select it, causing the rows to be sorted based on the contents of that column. You will usually want to sort by the “Self” or “Total” columns in this window. You can also select ascending or descending sort order using the direction triangle that appears at the right end of the selected header.
Results Table— The results table summarizes your samples in a simple, tabular form. User space code is normally listed in black text while supervisor code (typically the Mac OS X kernel or driver code) is listed in dark red text. However, this color scheme can be adjusted using the Advanced Settings, described below in “Profile Display Preferences.”
The Edit→Find→Find command (Command-F) and the related Edit→Find→Find Next (Command-G) and Edit→Find→Find Previous (Command-Shift-G) commands are very useful when you are searching for particular entries in a profile browser listing many symbols. Simply type the desired library or symbol name into the Find... dialog box, and Shark will automatically find and highlight the next instance of that library or symbol.
The table consists of five columns:
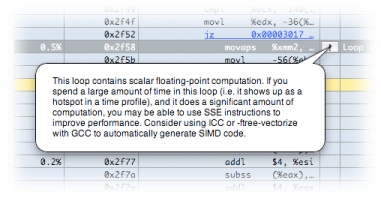
Code Tuning Advice— When possible, Shark points out performance bottlenecks and problems. The availability of code tuning advice is shown by a
 button in the Results Table. Click on the button to display the tuning advice in a text bubble, as shown in “ISA Reference Window.”
button in the Results Table. Click on the button to display the tuning advice in a text bubble, as shown in “ISA Reference Window.”Self— The percentage of samples falling within this granule (i.e. symbol) only. Sorting on this column is a good way to locate the functions that were actively executing the most, and as a result is a good choice for use with the bottom-up “Heavy” view. By double-clicking on this, you can view the raw number of samples for each row in the table.
Total— In the “Heavy” view, this column lists the portion of each leaf entry’s time that passes through the given function (at the root level, therefore, it is equal to the Self column). In the “Tree” view this column lists the percentage of samples that landed in the given granule or anything called by it (self plus descendants or “children”). Sorting on this column is a good way to locate the top of callstack trees rapidly, and as a result is a good choice for use with the top-down “Tree” view. By double-clicking on this, you can view the raw number of samples for each row in the table.
Library— The name of the library (binary file) where the code of the sampled symbol is located. If no library information is available — unlikely but not impossible — the address of the beginning of the library is shown, instead.
Symbol— The symbol where this sample was located. Most of the time, this is the name of the function or subroutine that was executing when the sample was taken, but the precise definition is controlled by the compiler. One particular area for wariness is with macros and inline functions. These will usually be labeled according to the name of the calling function, and not the macro or inline function name itself. If no symbol information is available, the address of the beginning of the symbol is shown, instead.
You may click the disclosure triangle to the left of the symbol name to open up nested row(s) containing the name of all caller(s) (“Heavy” view) or callee(s) (“Tree” view). If you Option-Click on the triangle, instead, then all disclosure triangles nested within will open, too, allowing you to open up the entire stack with a single click.
Status Bar— This line shows you the number of active samples, the number of samples in any selected row(s) of the Results Table, and the percent of samples that are selected. Note that the number of active samples being displayed can be reduced dramatically using controls such as the Process pop-up, Thread pop-up, and data mining operations (see “Data Mining”).
Callstack View Button— Pressing this button opens up the function Callstack Table, shown in Figure 2-6, which allows you to view deep calling trees more easily. The most frequently occurring callstack within the selected granule (address/symbol/library) is displayed. Once open, you can click rows of the Callstack Table to navigate quickly to other granules that are present in the selected callstack.
Process Popup Menu— This lists all of the sampled processes, in order of descending number of samples in the profile, plus an “All” option at the top. When you choose an option here, the Results Table is constrained to only show samples falling within the selected process. Each entry in the process list displays the following information: the percent of total samples taken within that process, process name, and process ID (PID). This information is similar to the monitoring information provided by tools such as the command-line
topprogram.Thread Popup Menu— When you select a single process using the Process Popup, this menu lets you choose samples from a particular thread within that process. By default, the samples from all of the threads within the selected process are merged, using the “All” option.
View Popup Menu— This popup menu lets you choose from among the two different view options (“Heavy” and “Tree”) described below, or to split the window and display both views at once (“Heavy and Tree”).
Heavy View
The “Heavy” view is not flat – each symbol name has a disclosure triangle next to it (closed by default). Opening the disclosure triangles shows you the call path or paths that lead to each function. This allows you first to understand which functions are most performance-critical and second to see the calling paths to those functions.
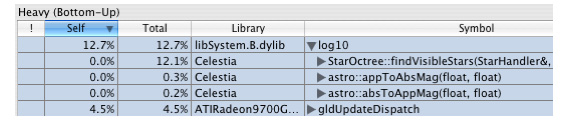
For example, Figure 2-7 shows a close-up of the “Heavy” profile view log10() entry. The library function log10() represents 12.7% of the time spent in the Celestia process. The 12.7% of the overall time spent in log10() is distributed between three calling paths. The Total column shows that the first path (through StarOctree::findVisibleStars()) accounts for 12.1% of the overall time. The rest of the total time spent in log10() is through calls made by two other functions in the example shown above
Tree View
In addition to the default “Heavy” or bottom-up profile view, Shark supports a call tree or top-down view (select “Tree” in the Profile View pop-up button).
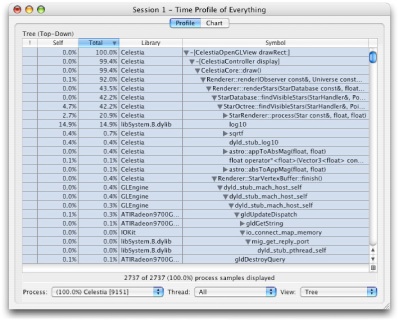
The “Tree” view gives you an overall picture of the program calling structure. In the sample profile (Figure 2-8), the top-level function is [CelestiaOpenGLView drawRect:], which in turn calls [CelestiaController display], which then calls CelestiaCore::draw(), and so on.
In “Tree” view, the Total column lists the amount of time spent in a function and its descendants, while the Self column lists the time spent only inside the listed function.
Note on Heavy/Tree comparisons: Please note that there may not be a one-to-one correspondence between entries in “Tree” view and “Heavy” view. If you select a function in “Heavy” view and then switch to “Tree” view, it will always select exactly one function in the tree. On the other hand, if you select a function in “Tree” view and then switch back to “Heavy” view, Shark will automatically select the “heaviest” symbol corresponding to that callpath. If several callpaths have similar weights, Shark may end up selecting one that is surprising to you.
Profile Display Preferences
Profile analysis can help you better understand the data presented in the Profile Browser by tailoring the formatting of the sampled information to suit your application’s code. Analysis settings are controlled separately for each session. The analysis controls are accessed per session by opening a drawer on the Profile Window, shown in “Advanced Session Management and Data Mining,” using File→Show Advanced Settings (Command-Shift-M).
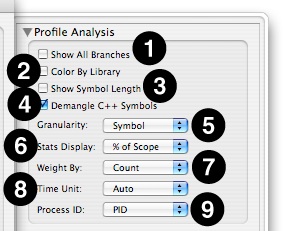
This part of the Advanced Settings drawer contains many different controls:
Show All Branches— The default “Heavy” view lists only the leaf entries (where samples landed) for the sampled callstacks. As a result, each sample only appears once in the profile. Opening disclosure triangles in the “Heavy” view reveals the contribution of each calling function to the “leaf” function’s total, if you are interested in seeing what is calling those functions. With Show All Branches on, a “sample” is counted for all symbols (root, interior and leaf), rather than only leaf entries. This results in actual samples with deep callstacks being over-represented in the profile, since they are counted many times, but makes it easier to find symbols for frequently-occurring but non-leaf functions, since one no longer must drill down through multiple levels of disclosure triangles to find them.
While Shark will allow you to use this mode with “tree” view, it is not recommended.
Color By Library— Uses colors to differentiate libraries in the Results table.
Show Symbol Length— Displays the sum of instruction lengths in bytes for each symbol.
Demangle C++ Symbols— Translates compiler-generated symbol names to user-friendly names in C++ code, stripping off the name additions required to support function polymorphism.
Granularity— Determines the grouping level that Shark uses to bind samples together.
Address— Group samples from the same program address.
Symbol— Group samples from the same symbol (usually there is a one-to-one correspondence between symbols and functions).
Library— Group samples from the same library.
Source File— Group samples from the same source file.
Source Line— Group samples from the same line of source code.
Stats Display— Selects units and a baseline number of samples.
Value— Shows raw sample counts rather than percentages.
% of Scope— Shows percentages based on currently selected process and/or thread.
% of Total— Shows percentages based on total samples taken.
Weight By— In Shark’s default weighting method (weight by sample count), each sample contributes a count of one. During sample processing, any time a sample lands in a particular symbol’s address range (in the case of symbol granularity) the total count (or weight) of the granule is incremented by one. In addition to context and performance counter information, each sample also saves the time interval since the last sample was recorded. When samples are weighted by time, each granule is weighted instead by the sum of the sampling interval times of all of its samples.
Time Unit— Selects the time unit (µs, ms, s) used to display time values. Auto will select the most appropriate time unit for each value when weighting by “Time.”
Process ID— Shark normally differentiates between processes according to their process ID (PID) – a unique integer assigned to each process running on the system. Thus, Shark groups together samples from the same PID. Shark can also identify processes by name. In this case, samples from processes with the same name (and possibly different PIDs) would be grouped together. This is particularly useful for programs that are run from scripts or that fork/join many processes.
The remainder of the controls visible in the Advanced Settings Drawer, which control Data Mining, are described in “Data Mining.”
Chart View
Click Shark’s Chart tab to explore sample data chronologically, from either a thread- or CPU-based perspective. This can help you understand the chronological calling behavior in your program, as opposed to the summary calling behavior shown in the Results Table. Using this chart, you can see at a glance if your program rarely/often calls functions and if there are any recurring patterns in the way your program calls functions. Based on this, you can often visually see different phases of execution — areas where your program is executing different pieces of its code. This information is useful, because each phase of execution will usually need to be optimized in a different way.
Shark’s Chart and Profile views are tightly integrated. The same level of scope (system/process/thread) is always displayed on both. Selected entries in the Results Table are highlighted in the Chart view. Filtering of samples using the Profile Analysis or Data Mining panes (see “Data Mining”) also affects the selection of samples shown in the Chart view. As with the Callstack Table shown in the Profile Browser, double clicking on any entry in the table opens a new Code Browser tab.
By default, Shark displays the currently selected scope (system, process, or thread) against an “absolute” time x-axis. This view displays gaps wherever the currently selected process or thread was not running. Use the Time Axis pop-up button to switch between absolute and relative time, which compresses out these out-of-scope areas.
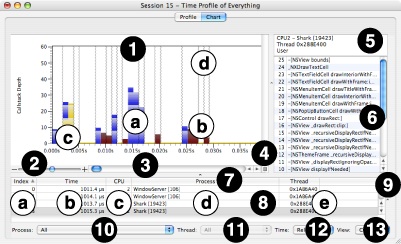
The chart view shown in Figure 2-10 has several parts:
Callstack Chart— This chart displays the depth (y-axis) of the callstack for each sample, chronologically from left-to-right over time (x-axis). The figure also clearly shows several key features of the chart:
User Callstack— Most callstacks, in blue, represent user-level code from your program.
Supervisor Callstack— Callstacks in dark red represent supervisor-level code stacks that were sampled.
Selected Callstack— A yellow “pyramid” of callstacks is highlighted when you click on the graph to select a sample. Once you have chosen a sample, you can use the left and right arrow keys to navigate to the previous or next unique callstack “pyramid.” After highlighting the chosen sample, Shark examines the callstacks to either side and automatically extends the selection outwards to the left and right wherever the adjacent callstacks have the same symbol. In this way, you can easily see the full tenures for each function (length of time that function is in the callstack). Because functions at the base of the callstack, like
main, have much longer tenures than the leaf functions at the top of the callstack, the shape of the highlighted area will always be a pyramid of some sort.It is also possible to select one or more individual symbols within the chart view by selecting them in the Profile Browser and then switching over to the chart view. After you switch to the chart view, all of the dots on the chart representing calls to the selected symbol(s) will be highlighted in yellow, allowing you to find and examine samples containing those symbol(s) more easily in complex charts. It is usually easy to differentiate these “symbol selections” from the “sample selections” made by clicking within the chart view itself, because only elements of each callstack corresponding to the selected symbols are highlighted in the former case, and not entire samples or “pyramids,” as in the latter.
Context Switch Lines— These lines indicate where the operating system switched another process or thread into the processor. Note that because Shark uses statistical sampling, it is possible to miss very short thread contexts. They are only visible at high levels of magnification in “absolute” time mode (as chosen in #12, below), when you select the option to show them in the Advanced Settings.
Out-of-Scope Callstack— (not shown) Callstacks in gray, visible only in “absolute” time mode, are just placeholders for samples that are outside the current process/thread scope. In “relative” mode, they are eliminated from the graph.
Zoom Slider— You can zoom in or out of the chart by dragging this slider towards the “+” and “–” ends, respectively. You can also use the mouse to zoom into a subset of the displayed samples by dragging the mouse pointer over the desired region of the chart. Zooming out can also be accomplished by Option-Clicking on the chart.
Chart Scroll Bar— If you have magnified the chart, then you can use this scroll bar to move left-and-right within it.
Callstack Table Button— Press this button to expose or collapse the Callstack Table, below.
Callstack Table Header— This area summarizes the CPU number, process ID, thread ID, and user/supervisor code status of the sample. This is displayed or hidden using the Callstack Table Button (#4).
Callstack Table— This displays the functions within the callstack for the currently selected sample, with the leaf function at the top and the base of the stack at the bottom. As you select different samples in the chart, this listing will update to reflect the location of the current selection. This is displayed or hidden using the Callstack Table Button (#4).
Sample Table Headers— Like most tables in Shark, you can click here to select the column used to sort the samples in this table, and then click on the arrow at the right end of the selected header cell to choose to sort in ascending or descending order. Choosing a column here has no other effect besides controlling the sort order, however.
Sample Table— This table lists a summary of all samples recorded within the session. It lists several key facts that are recorded with each sample:
Index— Number of the sample within the session, starting from 1 and going up.
Time— Time that has passed between this sample and the previous one. Normally, this will be a constant amount of time equal to the sampling period, but there are some sampling modes that allow variation here.
CPU— Number of the CPU on your system where this sample was recorded, starting from 1 and going up.
Process— Process ID for this sample’s process, including the name of the application.
Thread— Thread ID for this sample’s thread.
Sample Table Callstacks— If you pull this window splitter to the left, you will expose a table listing all symbol names within the callstacks of each sample, in a large grid. Effectively, this is like looking at multiple Callstack Tables rotated 90 degrees and placed side-by-side. Most of the time, this level of detail about your samples is not necessary, but there may be some occasions when you might find this view helpful.
Process Popup Menu— This lists all of the sampled processes, in order of descending number of samples in the profile, plus an “All” option at the top. When you choose an option here, the Callstack Chart is constrained to only show samples falling within the selected process. Each entry in the process list displays the following information: the percent of total samples taken within that process, process name, and process ID (PID). This information is similar to the monitoring information provided by tools such as the command-line
topprogram.Thread Popup Menu— When you select a single process using the Process Popup, this menu lets you choose samples from a particular thread within that process. By default, the samples from all of the threads within the selected process are merged, using the “All” option.
Time Popup Menu— This popup lets you choose between two different viewing modes. The first, “absolute” time mode, shows all samples from a particular processor, no matter what was executing. Samples from outside the current process/thread scope are grayed out, but are still plotted. On the other hand, in “relative” time mode, all out-of-scope samples are eliminated and the chart’s x-axis is adjusted to account for the smaller number of samples.
View Popup Menu— This popup lets you choose to view sets of samples from different processor cores.
Advanced Chart View Settings
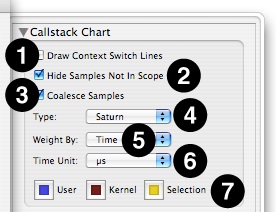
The first pane of the Advanced Settings drawer displays a new set of options if you switch to a Chart view (Figure 2-11). These controls affect the appearance of the chart, and are generally fairly minor:
Draw Context Switch Lines— Enables or disables the drawing of gray lines between samples that are from different process and/or thread contexts. They are quite useful, but can clutter the display at low levels of magnification.
Hide Samples Not In Scope— When chosen, this hides all samples from processes or threads outside of the ones in the current scope, as chosen by the Process and Thread pop-up menus. Any remaining samples are compressed together to remove any gaps. This process is similar to switching to “Relative” time using the Time pop-up menu, but the results are slightly different.
Coalesce Samples— When chosen, this combines adjacent samples containing the same callstacks together, so they are no longer individually selectable. If your Time Profiles often contain large blocks of identical samples, the use of this option can make maneuvering through the samples using the arrow keys somewhat easier.
Chart Type— Selects which type of chart to plot. You will rarely need to change this, but other options are available:
Saturn— The default chart type, this presents a graph consisting of a solid bar representing the callstack at each sample point.
Trace— This chart type is similar to the Saturn graph type, except that it only draws an outline around the bars instead of coloring them completely. Selections are made only on a sample-by-sample basis, instead of in “pyramids.”
Delta— This is much like the trace view, including the point selections. However, it only shows changes in the callstacks, and not their exact depth. As a result, it is of most use when you are looking for rare changes in the callstack depth or trends over time.
Hybrid— This graph looks like a Trace graph, but uses the full “pyramid” selection capability of the Saturn graph type.
Weight By— Choose how to present the x-axis scale for the chart view. You may have Shark present this axis in terms of sample count or by time. You may also use the keyboard equivalents Command-1 to use sample counts or Command-2 to use time.
Time Unit— Selects the time unit to use in the Time column of the Sample Table. Normally you should just leave this on the default, “Auto,” but if you would prefer you may explicitly choose to have the numbers displayed in µs, ms, or s.
Color Selection— Choose colors to use for user sample callstacks, kernel sample callstacks, and the selection area by clicking on these color wells.
The remainder of the controls visible in the Advanced Settings Drawer, which control Data Mining, are described in “Data Mining.”
Code Browser
Double-clicking on an entry in the Results Table or Callstack Table will open a Code Browser view for that entry, as shown in Figure 2-12. If available, the source code for the selected function is displayed. Source line and file information are available if the sampled application was compiled with debugging information (see “Debugging Information”). The Code Browser shows the code from the selected function and colorizes each instruction according to its reference count (the number of times it was sampled).
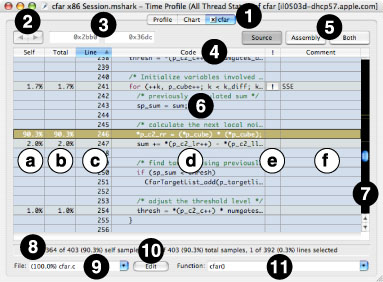
The Code Browser window consists of several different parts:
Code Browser Tab— When you double-click on an entry in a Profile Browser or Chart View, Shark dynamically adds a tab to the top of the window. This tab contains the code browser for the symbol that you double-clicked. If you return to one of the original browsers and double-click on another symbol, another tab will be added for that symbol. Unlike the default tabs, these additional tabs all have small close boxes on the left end. When clicked, the tab will be eliminated. If you open up more than about 3–5 code browsers, this may be necessary because of limited space at the top of the window.
Browse Buttons— You can use these buttons to maneuver through function calls. After you double-click on a function call (denoted by blue text) and go to the actual function, the “back” button here (left arrow) will be enabled. To return to the caller, just click on the “back” button. After you have maneuvered through a function call, you can navigate through code forward and backward just as you would navigate web pages in a web browser.
Address Range— This is used with the Assembly Browser (see “Assembly Browser”).
Code Table Headers— Click on any column title to select it, causing the rows to be sorted based on the contents of that column. You will usually want to sort by the “Line” column in this window, so that you can view your code in the original sequence order. You can also select ascending or descending sort order using the direction triangle that appears at the right end of the selected header.
View Buttons— Use these buttons to choose between:, Assembly View, or a split-screen view showing both side-by-side.
Source View: This displays the original source code for the function. It is the default, if Shark can find source code for the function. To make sure that Shark can find your source, you first need to have debugging information enabled in your compiler (see “Debugging Information”). Also, it is best to avoid moving the files after you compile them, so all source paths embedded in debugging information will still be accurate. Otherwise, you may need to adjust Shark’s source paths, as described in “Shark Preferences.”
Assembly View: This displays the raw assembly language for the function. Because it is extracted directly from the program binary, this option is always available, even for library code. See the Assembly Browser section (“Assembly Browser”) for more information.
Both: This displays both views side-by-side, and is useful when you are comparing your source input to the compiler’s output.
Code Table— This table allows you to examine your source code and see how samples were distributed among the various lines of code. Each row of the table is automatically color-coded based on the number of samples associated with that line — by default, hotter colors mean more samples — allowing you can see at a glance which code is executing the most.
You can use the Edit→Find→Find command (Command-F) and the related Edit→Find→Find Next (Command-G) and Edit→Find→Find Previous (Command-Shift-G) commands to search through your code, much like you can in most text editors. Just type the desired text into the Find... dialog box, and Shark will automatically find and highlight the next instance of that text in your code. You can also use this to search for comments, if you need to look for repeated instances of a tip in the comments, for example.
The table consists of several columns. Some of these are optional, and are enabled or disabled using checkboxes in the Advanced Settings drawer.
Self— This optional column lists the percentage of displayed references for each instruction or source line, using only the samples that fell within this particular address range. To see sample counts instead of percentages, double-click on the column.
Total— This optional column lists the percentage of displayed references for each instruction or source line, including called functions. To see sample counts instead of percentages, double-click on the column.
Line— The line number for each line from your original source code file. This column is particularly useful for sorting the browser window, in order to keep the line numbers there in sequence.
Code— This column lists your original source file, line-by-line. Double-clicking on this column will take you to the equivalent location in the Assembly display. Double-clicking on any function calls (denoted by blue text), will take you to the source code for that function.
Code Tuning Advice— When possible, Shark points out performance bottlenecks and problems. The availability of code tuning advice is shown by a
button in this column. Click on the button to display the tuning advice in a text bubble, as shown in “ISA Reference Window.” The suggestions provided in the code browser will usually be more detailed and lower-level than the ones visible within the profile browser.Comment— This column gives a brief summary of the code tuning advice, allowing you to determine which code tuning suggestions are likely to be helpful without clicking on every last advice button.
Performance Event Column— (Not shown) This optional column, which is only available when you are looking at a code browser while using a configuration that uses performance counters (as described in “Event Counting and Profiling Overview”), shows raw counts from those counters. It cannot be enabled with normal time profiles.
Code Table Scrollbar— This scrollbar (Figure 2-13) is customized to show an overview of sampling hot spots; the brightness of a location in the scrollbar is proportional to the sampling reference count of the corresponding instruction in the Code Table. Since programmer time is best spent optimizing code that makes up a large portion of the execution time, this visualization of hot spots helps you to quickly see and focus your development effort on the code that has the greatest influence on overall performance.
Status Bar— This line shows you the number of active samples in the currently displayed memory range, the number of active samples in the entire session, and/or the number of samples in any selected row(s) of the Code Table. Either or both of the active samples will be eliminated from this line if the “Self” or “Total” columns in the code table are disabled. In addition, the percent of samples that are in each of these categories is displayed.
Source File Popup Menu—A given memory range can contain source code from more than one file because of inlining done by the compiler. You can select which source file to view using this menu.
Edit Button— You can open the currently displayed source file in Xcode by selecting the Edit button. The file will open up and scroll to your selected line, or the line with the most samples if nothing is selected.
Function Popup Menu— This pop-up menu allows you to jump quickly to different functions in the current source file. Please note that sample counts are only shown for the source lines in the current memory range — other functions not in the current memory range may be visible, and you can still look at them, but they will show no sample counts).
Assembly Browser
In addition to displaying the source code from the current memory range, Shark also provides a detailed assembly-level view (Figure 2-14) that can be enabled by clicking on the Assembly button or combined with a source browser by clicking on the Both button. This browser will also pop up in place of a source browser if Shark cannot find source code for the address range that you are examining. This will often be the case with common system libraries, the kernel, and precompiled applications.
Often, it is useful to examine the relationship between a line of source code and its compiler-generated instructions. Shark encourages this type of exploration: either use the Both button to view source and assembly simultaneously or double-click on a line in the Source or Code columns in the Assembly Code Browser to jump to the corresponding source line in the Source Code Browser. Conversely, double-click on a line of code in the Source Code Browser to jump back to the corresponding instructions in the Assembly Code Browser.
Many parts of this browser are identical to their counterparts in the Source Browser, including Self, Total, tuning advice, and Comment columns. However, there are a few differences:
Browse Buttons— You can use these buttons to maneuver through branches. After you double-click on a branch with a static target address (denoted by blue text) and go to the destination, the “back” button here (left arrow) will be enabled. To return to the branch itself, just click on the “back” button. After you have maneuvered through branches, you can navigate through code forward and backward just as you would navigate web pages in a web browser.
Address Range— Samples are displayed only for the address range between these two boxes (usually one symbol). Code outside of this range may have samples, but they will not be displayed.
Code Table— About half of the columns have functions that are identical to the basic source browser, but the others are new or slightly different:
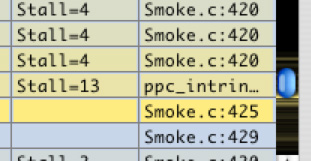
Address Column— This displays the address of the assembly-language instruction displayed on this row. With PowerPC, this value simply increases by 4 with every row, but with x86 this will change by 1–18 bytes per row, depending upon the variable length of each instruction. You can double-click on this column to switch to relative decimal or hexadecimal offsets from the beginning of the address range.
Code Column— This column displays the assembly code used by your routine. Using Advanced Settings, you can choose to disable disassembly and to have Shark automatically find and indent loops based on backwards branches in the code (the default). Within this column, you can double-click on a branch with a static target address (denoted by blue text) to follow a branch to its target address; after double-clicking, the function containing the target instruction will be loaded, if necessary, and the target instruction will be highlighted. Finally, double-clicking on this column will take you to the equivalent location in the corresponding Source display.
Cycles Column— (not shown) This PowerPC-only column displays the latency (processor cycles before an instruction’s result is available to dependent instructions) and repeat rate (processor cycles between completing instructions of this type when the corresponding pipeline is full) of the assembly instruction on this line, in processor cycles. In general, you will want to minimize the use of instructions with high latency, especially if the values that they produce are used by immediately following instructions. Use of instructions with poor (high number) repeat rates may also impact your performance if you try to issue them too frequently.
Comment Column— In addition to its usual function of providing short versions of the code analysis tips, on PowerPC the comment column also displays information about how long the instruction must stall as a result of long latency by prior instructions. You will find that very low-level optimization hints, focused on particular assembly instructions, are provided here.
Source Column— This shows the source file name and line number of where in the source code this instruction originated, when this is available. As with the Code Column, you can double-click here to get back to the Source display, scrolled to the line listed here.
Asm Help Button— Press this button to get help for the selected assembly-language instruction, as described in “ISA Reference Window.”
Advanced Code Browser Settings
The Advanced Settings drawer displays a new set of options if you switch to a Code Browser view (“Manual Session Symbolication”). These options allow you to customize the viewing of source and assembly code and turn on and off various features of the browser. These are many controls in this view:
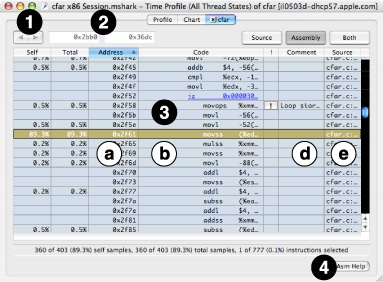
Code Browser— This section affects the display of both source and assembly-language browsers.
CPU Model— By default, Shark uses a model of the current system’s CPU architecture when analyzing code sequences in order to determine instruction latencies and hints. You can select other CPU architectures by changing this setting.
Hot Code Colors— Choose the colors that Shark uses to display the “hotness” of code here.
Selection Formatting— Choose the color and whether or not an outline is used for code selections.
Grid Lines— Adds grid lines between each line of code when checked (the default).
Show Total Column— Toggles display of the column that lists the percentage of displayed references for each instruction or source line, including called functions.
Show Self Column— Toggles display of the column that lists the percentage of displayed references for each instruction or source line, but not including called functions.
Show Perf Event Column(s)— If the current profile contains performance counter information, this setting toggles display of that data within the browser. Otherwise, it will be disabled.
Show Code Analysis Columns— Toggles display of the columns that provide optimization tips.
Source Browser— This section affects the display of the source browser only.
Line Numbers— Toggles display of the column that lists the line number from the source code.
Syntax Coloring— Enable this to have Shark color source code keywords, constants, comments, and such.
Tab Width— Shark auto-indents loops by this number of spaces for every loop nest level.
Asm Browser— This section affects the display of the assembly-language browser only.
Disassemble— Choose whether to display disassembled mnemonics or raw hexadecimal values for the instructions.
Indent Loops— Choose whether or not to have Shark auto-indent loops in the code here. Loops are found based on analysis of backwards branches in typical compiled code.
Simplified Mnemonics— (PowerPC-only) Choose whether or not to enable full disassembly of instructions with constant values that specify special instruction modes, or to only disassemble to fundamental opcodes and leave the modifying constants intact for your examination.
Show G5 (PPC970) Dispatch Groups— (PowerPC-only) Displays outlines on the main assembly-language grid showing the breakdown of the instructions into dispatch groups. Further details on is can be found in “Code Analysis with the G5 (PPC970) Model.” This function is always disabled for sessions recorded on Macs with other processor architectures.
Show G5 (PPC970) Details Drawer— (PowerPC-only) Shark can display graphs of instruction dispatch slot and functional unit utilization in an additional, G5-specific “details” drawer. Further details on is can be found in “Code Analysis with the G5 (PPC970) Model.” This function is always disabled for sessions recorded on Macs with other processor architectures.
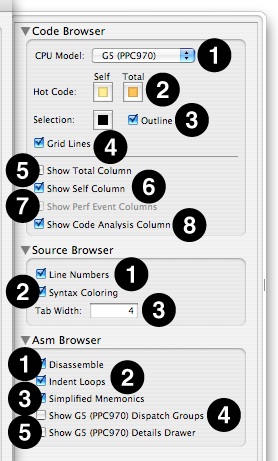
Other architectures have slightly different options for items 3–5 of the Asm Browser settings. For x86-based systems, illustrated in , these options are:
Syntax— Chooses whether to display the x86 instructions in Intel assembler syntax or AT&T syntax (the default).
Show Prefixes— If checked, instruction prefixes (like
lockand temporary mode shifts) will be displayed.Show Operand Sizes— If checked, each instruction explicitly encodes its operand size into the mnemonic (AT&T syntax) or operand list (Intel syntax). Otherwise, the code will be streamlined but it may not be possible to tell 8, 16, 32, and 64-bit versions of instructions apart.
For ARM-based systems, illustrated in , the only option is:
ISA— Selects to decode the instructions in the block as ARM (32-bit) instructions or Thumb (16-bit) instructions. The iPhone OS uses both types of ARM instructions for different functions, so you may need to use this menu to switch from one to the other on a symbol-by-symbol basis.
ISA Reference Window
In order to understand the low-level analysis displayed in Shark’s Assembly Browser, it may be helpful to view the underlying machine’s instruction set architecture (ISA). You can display the PowerPC or Intel ISA Reference Manual (Figure 2-18) by clicking on the Asm Help button in the Assembly Browser or choosing the appropriate command from the Help menu: Help→PowerPC ISA Reference, Help→IA32 ISA Reference, or Help→EM64T ISA Reference.
The ISA Reference Window provides an indexed, searchable interface to the PowerPC, IA-32 (32-bit x86), or EM64T (64-bit x86) instruction sets. The reference is also integrated with selection in the Shark Assembly Browser – selecting an instruction in the table causes the ISA Reference Window to jump to that instruction’s definition in the manual.

Tips and Tricks
This section points out a few things that you might see while looking at a Time Profile, what they may mean, and how to optimize your code if you see them. The tips and tricks listed herein are organized according to the view most commonly used to infer the associated behavior.
Profile Browser
Where should I start? :
When first presented with a Profile Browser, you will want to begin in “Heavy View” sorted by “Self” and see what pops to the top. These will be the functions that execute the most, and probably have inner loops that may be susceptible to optimization. Do not forget to pop open disclosure triangles to see what functions are calling these functions; sometimes it is easier to optimize outer loops in these calling functions, instead of inner loops in the leaf functions. If any of these outer functions look promising, you may want to consider flipping to “Tree” view in order to see the caller-callee relationships a little more clearly.
No Samples Taken:
Shark will come up and report that it has not taken any samples if all of the threads in your application are blocked when you choose to sample one process using “Process Attach” or “Process Launch.” In this case, you probably want to use Time Profile (All Thread States) (see “Time Profile (All Thread States)”) to see where your threads are blocking.
If you are using programmatic control of Shark’s start and stop points (see “Programmatic Control”), having no samples taken may also indicate that you are starting and stopping so quickly that there was simply no chance to take any meaningful samples. In this case, you should either adjust your start and stop points to increase the amount of time between them, increase the sampling rate (see “Taking a Time Profile”), or both.
Too many symbols displayed:
If there is just too much clutter in the profile browser, then you need to use data mining. See “Data Mining” for details on how to do this. Sometimes, switching between “Tree” and “Heavy” view can help organize the symbols in a more helpful way, also.
If you are looking for a small number of known symbols in a large browser window, the Edit→Find→Find command (Command-F) and the related Edit→Find→Find Next (Command-G) and Edit→Find→Find Previous (Command-Shift-G) commands are probably your best bet. With these commands, Shark will automatically find and highlight the next instance of that library or symbol for you.
Lots of symbols have almost equal weight:
If you have many symbols popping up to the top of the list, the best thing is to quickly examine several of them using the Code Browser, while keeping an eye out for functions with loops that look easy-to-optimize.
Chart View
Different parts of the chart look visibly different:
Different-looking areas were probably created by different code in your program as it executes different program phases of execution. In most applications, each of these will need to be optimized separately. As a result, you may want to sample these with different Shark sessions, so that you can examine the different phases separately. Alternately, you may sample them all in one session and then use data mining (see “Data Mining”) to focus more selectively on each phase as you examine the session.
What is executing at a point in the chart? :
Click on the chart at the point of interest and then open up the Callstack Table to see the stack for that sample (#4–6 in Figure 2-10). You can also double-click on the chart to open a Code Browser for the function executing at that point.
Code Browser
The assembly browser shows lots of MOV (x86) or LD/ST (PowerPC) instructions:
If well over half of the instructions in your Assembly Browsers are memory access instructions, instead of actual computation, then it is quite likely that you forgot to turn on compiler optimization. One of the most important compiler optimizations is register allocation, which assigns variables to processor registers temporarily between operations. Without this — such as when you use Xcode’s
gccwith-O0optimization — the compiler will typically load and store all values to-and-from memory with every operation, resulting in multiple data movement instructions per computation instruction. WIth register allocation, however, the compiler will use registers to route data right from one computation instruction directly to another, resulting in significantly fewer instructions and hence faster code.As a result of the significant “free” performance improvement possible using this and other optimizations, we suggest that you always use compiler optimization before using Shark (with Xcode’s
gccwe suggest-O2,-Os, or-O3).I do not see any source:
Shark finds source code based on the full path to the source at the time it was compiled, but it recovers this source as you examine the session. If your source code moved or changed between compilation and session examination, or if you are recording and examining your session on a different Mac than you used for compilation, then you are likely to have trouble finding source. In this case, you will want to either recompile your source, in order to reset the paths correctly, or add the path to your source to Shark’s list of source search paths, in “Shark Preferences.”
Another common source of this problem is omitting the
-gflag when you compile. You should only use Shark on fully-optimized, release-quality code, but default settings in development environments such as Xcode often turn off debugging options like-gwhen set to produce optimized code. As a result, you will often need to manually adjust the build settings to enable this option when using Shark. Please note that in Xcode you will need to adjust the build settings for the Target that you are testing and the correct (optimized) build configuration. Unfortunately, it is quite easy to set options for the wrong target or build configuration accidentally.I want to see code coloring based on time spent here and in functions called by this code:
By default, the code browser only shows the Self value column, and code is colored based on these values, which are the percent of samples spent executing each line of code within the displayed function. If you are examining your code line-by-line, this is generally how you will want to see the weighting displayed. However, you may also be interested in seeing time spent within the function and all descendant functions that it calls. In this case, you will want to enable the Total column using the Advanced Settings drawer. The code browser’s color scheme will then change to show weight coloring based on the values in this column, instead.
Example: Optimizing MPEG-2 using Time Profiles
In this section, Shark is used to increase the performance of the reference implementation of the MPEG-2 decoder (from mpeg.org) by 5.7x on a Mac Pro with 3.0 GHz Intel® Core 2™ processor cores.
Before beginning any performance study, it is critical to define your performance metric and to justify its relevance. Measurement of your metric should be both precise and consistent. Our performance metric for MPEG-2 was defined as the frame rate, in frames per second, of the decoder when decoding a reference movie. Unlike most video decoders, our test harness for the mpeg.org reference code let it decode as quickly as possible, without trying to keep the frame rate fixed at the rate at which it was originally recorded. As a result, the frame rate was a direct function of how fast the processor was able to do the actual decoding. This kind of unlimited decoding speed is used for offline video decoding/encoding, a task performed almost constantly by video editing programs as they read and write video clips. In addition, higher decoding speed in playback settings where the processor is limited to a fixed frame rate is still a useful metric, because means that the processor will have more time between frames to do other tasks, decode larger frames, or simply shut down and save power for a longer time between frames.
Base
The reference MPEG-2 decoder source code consists of over 120 densely coded functions spread across more than 20 files. As a result, if one were handed the code and told to optimize it, the task would appear virtually hopeless — there is simply too much code to review in a reasonable amount of time! However, as in many programs, a large majority of the code handles initialization tasks and unusual corner cases, and is therefore only rarely executed. As a result, the actual quantity of code that needs modification in order to dramatically speed up the application is probably small, but Shark is required to locate it efficiently.
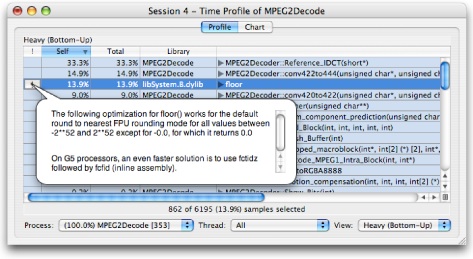
After compiling and running the reference decoder, Shark generated the session displayed in Figure 2-19. Just by pressing the “Start” and “Stop” button, we get a session that lets us see that about half the execution time is spent in a combination of the Reference_IDCT() function and the floor() function. By clicking the callout (![]() ) button to the left of the
) button to the left of the floor() function in the display, we see that Shark suggests we replace the floor() function with a simple, inline replacement. Following this advice garners a 1.12x performance increase. This is not a huge improvement, but is very good for something that only takes a few minutes to perform.
Looking at the code more closely shows whyfloor() was required: the IDCT (Inverse Discrete Cosine Transform) function takes short integer input, converts to floating point for calculation, and then converts the results back to short integers. While this is a good way to keep the mathematics simple in the sample “reference” platform, the numerous type conversions and slow floating point arithmetic make this routine slow.
Converting to integer mathematics throughout avoids expensive integer→FP→integer conversions and slow FP mathematics, at the expense of more convoluted math in the code. This code is available in the mpeg2play implementation (also available on mpeg.org). Switching the implementation to integer math resulted in a much more dramatic speedup over the original code of 1.86x.
Vectorization
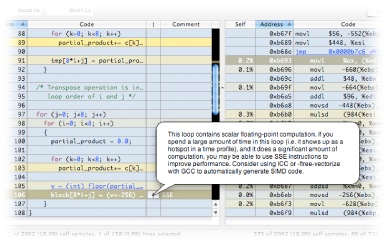
Optimizing the Reference_IDCT() function by converting it from floating point to integer also presented another possible optimization that could be helpful: SIMD vectorization. All Intel Macintoshes support the SSE instruction set extensions, allowing them to process 128-bit vectors of data, and most PowerPC Macintoshes support the very similar AltiVec™ extensions. Although the methodology for vectorizing your code is beyond the scope of this document, there is a plethora of documentation and sample code available to you online at http://developer.apple.com/hardwaredrivers/ve/index.html. The very regular, mathematically intensive inner loops of the IDCT routine are perfect candidates for this kind of vectorization. Following the suggestion supplied by Shark in Figure 2-20 led to converting the IDCT routine to use SSE. Surprisingly, performance only increased to 2.05x, with only a 10% improvement from vectorization.
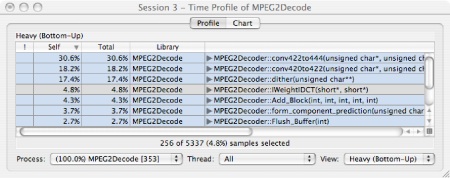
At a point like this, where our optimization efforts result in non-intuitive results, it is generally a good idea to use Shark again to see how conditions have changed since our first measurement. This additional run of Shark produced the session in Figure 2-21. The vectorized IDCT function, IWeightIDCT(), now takes up less than 5% of the total execution time. The mystery is solved: as the IDCT function was optimized while other routines were not modified, those other, unoptimized routines became the performance bottleneck instead. Further examination with Shark quickly identified the key loops in several new functions. Because, like IDCT, they were performing complex math in tight inner loops, most of the new bottlenecks were also good targets for vectorization. As seen in Table 2-1, final optimization of motion compensation (Flush_Buffer() and Add_Block()), colorspace conversion (dither()), and pixel interpolation (conv420to422() and conv422to444()) achieved a speedup of 5.69x over the original code — a dramatic improvement made possible in a relatively short amount of time thanks to the feedback provided by Shark.
Optimization Step | Speedup |
|---|---|
Original | 1.00x |
Fast | 1.12x |
Integer IDCT | 1.86x |
Vector IDCT | 2.05x |
All Vector | 5.69x |
© 2008 Apple Inc. All Rights Reserved. (Last updated: 2008-04-14)