Avoiding Buffer Overflows
Buffer overflows, both on the stack and on the heap, are a major source of security vulnerabilities in C, Objective-C, and C++ code. This article discusses coding practices that will avoid buffer overflow problems, lists tools you can use to detect buffer overflows, and provides samples illustrating safe code. This article assumes familiarity with the concepts of memory allocation and the program's heap and stack. For a higher-level discussion of the problem, see “Buffer Overflows.”
Contents:
The Source Of the Problem
String Handling
Calculating Buffer Sizes
Integer Overflow
Detecting Buffer Overflows
The Source Of the Problem
Local variables are allocated on the stack, along with parameters and linkage information (that is, where to resume execution after a function returns.) The exact content and order of data on the stack depends on the operating system and CPU architecture. When you use malloc, new, or equivalent functions to allocate a block of memory or instantiate an object, the memory is allocated on the heap.
Every time your program solicits input from a user, there is a potential for the user to enter inappropriate data. For example, they might enter more data than you have reserved room for in memory. If the user enters more data than will fit in the reserved space, and you do not truncate it, then that data will overwrite other data in memory. If the memory overwritten contained data essential to the operation of the program, this overflow will cause a bug that, being intermittent, might be very hard to find. If the overwritten data includes the address of other code to be executed and the user has done this deliberately, the user can point to malicious code that your program will then execute.
In the case of data saved on the stack, such as a local variable, it is relatively easy for an attacker to overwrite the linkage information in order to execute malicious code. An attacker can also modify local data and function parameters on the stack. Figure 1 illustrates a stack overflow in Mac OS X running on a PowerPC processor. For other processors, the details are different, but the effect is the same.
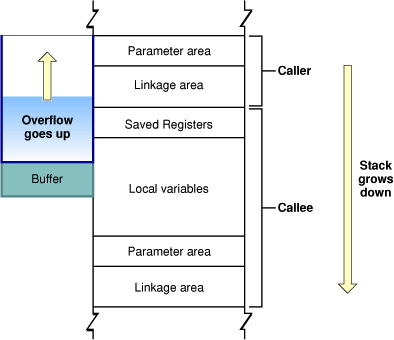
Because the data on the heap changes in a nonobvious way as a program runs, exploiting a buffer overflow on the heap is more challenging. However, many successful exploits have involved heap overflows. Attacks on the heap might involve overwriting critical data, either to cause the program to crash, or to change a value that can be exploited later (such as when a program temporarily stores a user name and password on the heap and an attacker manages to change them). In some cases, the heap contains pointers to executable code, so that by overwriting such a pointer an attacker can execute malicious code. Figure 2 illustrates a heap overflow overwriting a pointer.

Although most programming languages check input against storage to prevent buffer overflows, C, Objective-C, and C++ do not. Because many programs link to C libraries, vulnerabilities in standard libraries can cause vulnerabilities even in programs written in "safe" languages. For this reason, even if you are confident that your code is free of buffer overflow problems, you should limit exposure by running with the least privileges possible. See “Elevating Privileges Safely” for more information on this topic.
Keep in mind that obvious forms of input, such as strings entered through dialog boxes, are not the only potential source of malicious input. For example:
Buffer overflows in one operating system’s help system could be caused by maliciously prepared embedded images.
A commonly-used media player failed to validate a specific type of audio files, allowing an attacker to execute arbitrary code by causing a buffer overflow with a carefully crafted audio file.
[1CVE-2006-1591 2CVE-2006-1370]
String Handling
Strings are a common form of input and because many string-handling functions have no built-in checks for string length, strings are frequently the source of exploitable buffer overflows. Figure 3 illustrates the different ways three string copy functions handle the same over-length string. The strcpy function merely writes the entire string into memory, overwriting whatever came after it. The strncpy function truncates the string to the correct length, but without the terminating null character. When this string is read, then, all of the bytes in memory following it, up to the next null character, might be read as part of the string. Only the strlcpy function is fully safe, truncating the string and adding the terminating null character.
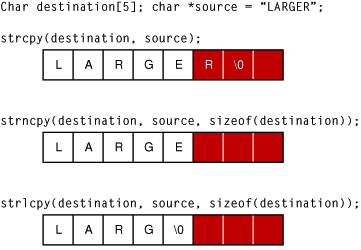
Table 1 summarizes the common C string-handling routines to avoid and which to use instead.
Don't use these functions | Use these instead |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
You can avoid string handling buffer overflows by using higher-level interfaces. If you are using C++, the ANSI C++ string class avoids buffer overflows, though it doesn't handle non-ASCII encodings (such as UNICODE). For Objective-C, use the NSString class. Note that an NSString object has to be converted to a C string in order to be passed to a C routine, such as a POSIX function. If you are writing code in C, you can use the Core Foundation representation of a string, referred to as a CFString, and the string-manipulation functions in the CFString API.
The Core Foundation CFString is “toll-free bridged” with its Cocoa Foundation counterpart, NSString. This means that the Core Foundation type is interchangeable in function or method calls with its equivalent Foundation object. Therefore, in a method where you see an NSString * parameter, you can pass in a value of type CFStringRef, and in a function where you see a CFStringRef parameter, you can pass in an NSString instance. This also applies to concrete subclasses of NSString. See CFString Reference, Foundation Framework Reference, and Carbon-Cocoa Integration Guide for more details on using these representations of strings and on converting between CFString strings and NSString objects.
Calculating Buffer Sizes
You should always calculate the size of a buffer and then make sure you don't put more data into the buffer than it can hold. The reason you should not assume a static size for a buffer is because, even if you originally assigned a static size to the buffer, either you or someone else maintaining your code in the future might change the buffer size but fail to change every case where the buffer is written to. The left column of Table 2 shows some code samples that assume a set buffer size. The right column shows a safer approach to achieving the same results.
In the first set of samples, a character buffer is set to 1024 bytes and, later in the program, the size of a block of data is checked before it is written to the buffer. This code is safe as long as the original declaration of the buffer size is never changed. However, if in a later version of the program a smaller size is assigned to the buffer, but the test is not changed, then a buffer overflow will result. The right column shows two safer versions of this code. In the first version, the buffer size is set using a constant that is set elsewhere and the check uses the same constant. In the second version, the buffer is set to 1024 bytes, but the check calculates the actual size of the buffer. In these cases, changing the original size of the buffer would not invalidate the check.
The second set of examples show a function that adds an .ext suffix to a filename. Both versions use the maximum path length for a file as the buffer size. The unsafe version in the left column assumes that the filename does not exceed this limit, and appends the suffix without checking the length of the string. The safer version in the right column uses the strlcat function, which truncates the string if it exceeds the size of the buffer.
Don't use this style | Use this style instead |
|---|---|
or
|
or
|
|
|
You should always use unsigned variables for calculating sizes of buffers and of data going into buffers. Because negative numbers are stored as large positive numbers, if you use signed variables an attacker might be able to cause a miscalculation in the size of the buffer or data by writing a large number to your program. See “Integer Overflow” for more information on potential problems with integer arithmetic.
For a further discussion of this issue and a list of more functions that can cause problems, see Wheeler, Secure Programming for Linux and Unix HOWTO (http://www.dwheeler.com/secure-programs/).
Integer Overflow
If the size of a buffer is calculated using data supplied by the user, there is a potential for a malicious user to enter a number that is too large for the integer data type, which can cause program crashes and other problems.
In twos-complement arithmetic, used by most compilers, a negative number is represented by inverting all the bits of the binary number and adding 1. A 1 in the most-significant bit indicates a negative number. Thus, for 4-byte signed integers, 0x7fffffff = 2147483647, but 0x80000000 = -2147483648
Therefore,
int 2147483647 + 1 = - 2147483648 |
If a malicious user specifies a negative number where your program is expecting only unsigned numbers, your program might interpret it as a very large number. Depending on what that number is used for, your program might attempt to allocate a buffer of that size, causing the memory allocation to fail or causing a heap overflow if the allocation succeeds. In an early version of a popular web browser, for example, storing objects into a JavaScript array allocated with negative size could overwrite memory. [CVE-2004-0361]
In other cases, if you use signed values to calculate buffer sizes and test to make sure the data is not too large for the buffer, a sufficiently large block of data will appear to have a negative size, and will therefore pass the size test while overflowing the buffer.
Depending on how the buffer size is calculated, specifying a negative number could result in a buffer too small for its intended use. For example, if your program wants a minimum buffer size of 1024 bytes and adds to that a number specified by the user, an attacker might cause you to allocate a buffer smaller than the minimum size by specifying a large positive number, as follows:
1024 + 4294966784 = 512 |
0x400 + 0xFFFFFE00 = 0x200 |
For some compilers, any bits that overflow past bit 31 are dropped; that is, 2**32 == 0. Because it is not illegal to have a buffer with a size of 0, and because malloc(0) returns a pointer to a small block, your code might run without errors if an attacker specifies a value that causes your buffer size calculation to equal 0 mod 2**32. In other words, for any values of n and m where n * m = 0 mod 2**32, allocating a buffer of size n*m results in a valid pointer to a buffer of size 0. In that case, a buffer overflow is assured.
To avoid such problems, you should put limits on any values the user can specify. When checking the validity of the values used to calculate a buffer size, you should include checks to make sure no integer overflow occurred. For example:
size_t bytes = n * m; |
if (n > 0 && m > 0 && int_max/n >= m) { |
... /* allocate “bytes” space */ |
} |
Detecting Buffer Overflows
To test for buffer overflows, you should attempt to enter more data than is asked for wherever your program accepts input. Also, if your program accepts data in a standard format, such as graphics or audio data, you should attempt to use malformed data. For example, if your program asks for a filename, you should attempt to enter a string longer than the maximum legal filename. Or, If there is a field that specifies the size of a block of data, attempt to use a data block larger than the one you indicated in the size field. If there are buffer overflows in your program, it will eventually crash. (Unfortunately, it might not crash until some time later, when it attempts to use the data that was overwritten.) Note that, although you can test for buffer overflows, you cannot test for the absence of buffer overflows; it is necessary, therefore, to check every input and every buffer size calculation in your code, as described in this article.
The crash log might provide some clues that the cause of the crash was a buffer overflow. If you enter a string of uppercase letters "A," for example, you might find a block of data in the crash log that repeats the number "41," the ASCII code for A (see Figure 4). If the program is trying to jump to a location that is actually an ASCII string, that's a sure sign that a buffer overflow was responsible for the crash.
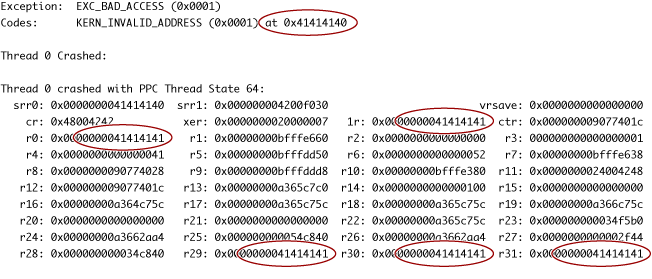
If there are any buffer overflows in your program, you should assume they are exploitable and fix them. It is much harder to prove that a buffer overflow is not exploitable than just to fix the bug.
© 2008 Apple Inc. All Rights Reserved. (Last updated: 2008-05-23)