Techniques for Working with Vertex Data
Complex shapes and detailed 3D models require large amounts of vertex data to describe them in OpenGL. Moving vertex data from your application to the graphics hardware incurs a performance cost that can be quite large depending on the size of the data set. Applications that use large vertex data sets can adopt one or more strategies to optimize how the data flows to OpenGL.

This chapter provides best practices for working with vertex data, describes how to use extensions to optimize performance, shows how to use a fence command to test for completion of OpenGL commands, and discusses how to set up double buffers.
In this section:
Best Practices for Working with Vertex Data
Using Extensions to Improve Performance
Double Buffering Vertex Data
See Also
Best Practices for Working with Vertex Data
Understanding how vertex data flows through an OpenGL program is important to choosing strategies for handling the data. Vertex data can travel through OpenGL in two ways, as shown in Figure 8-2. The first way, from vertex data to per-vertex operations, is as part of an OpenGL command sequence that is issued by the application and executed immediately (immediate mode). The second is packaged as a named display list that can be preprocessed ahead of time and used later in the program.
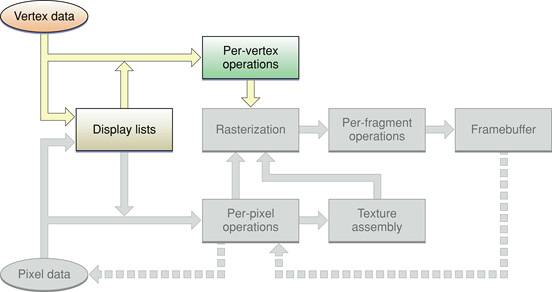
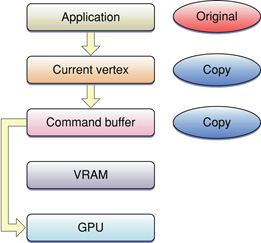
Figure 8-3 provides a closer look at the vertex data path when using immediate mode. Without any optimizations, your vertex data can be copied at various points in the data path. OpenGL is required to capture the current vertex state when you use immediate mode. If your code uses functions that operate on vertex arrays, you can eliminate the command buffer copy shown in Figure 8-3. The OpenGL commands glDrawRangeElements, glDrawElements, and glDrawArrays render multiple geometric primitives from array data, using very few subroutine calls. It's best to use glDrawRangeElements, with glDrawElements the second choice, and glDrawArrays the third.
In addition to using functions that operate on vertex arrays, there are a number of other strategies that you can adopt to optimize the flow of vertex data in your application:
Minimize data type conversions by supplying OpenGL data types for vertex data. Use
GLfloat,GLshort, orGLubytedata types because most graphics processors handle these types natively. If you use some other type, then OpenGL may need to perform a costly data conversion.The most desirable way to handle vertex data is to use the
GL_APPLE_vertex_array_rangeorGL_ARB_vertex_buffer_objectextensions. (See “Using Extensions to Improve Performance.”) If you can't use these extensions, then make sure you use vertex arrays and display lists. Avoid using immediate mode. But if your code must use immediate mode, maximize the number of vertices per draw command or within a begin-end code block.Use vertex programs to perform computations on vertex data instead of using the CPU to perform the computations.
If your code must use immediate mode, use CGL macros (for Cocoa or Carbon) or AGL macros (Carbon only). Macros use the function call dispatch table directly, which can dramatically reduce function call overhead. See “Use OpenGL Macros.”
Using Extensions to Improve Performance
The vertex array range (GL_APPLE_vertex_array_range) and vertex buffer object (GL_ARB_vertex_buffer_object) extensions were created to help streamline the vertex data path. Although both can improve application performance, the vertex buffer object extension should be your first choice and the vertex array range extension your second. The vertex array range extension provides the GPU with direct access to your data. When your data is dynamic, the burden is on your application to synchronize access to that data. Vertex buffer objects, on the other hand, don't require your application to synchronize data access, which is the primary reason why they are preferred. You'll read more about each extension in the sections that follow.
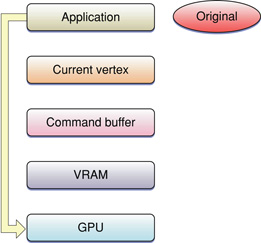
For dynamic vertex array data, these extensions set up DMA from the application to the GPU, as shown in Figure 8-4. Notice that copies of the vertex data are not maintained in VRAM. This means that each time the data is drawn, it gets moved from the application to the GPU. It's important to ensure that this happens asynchronously.
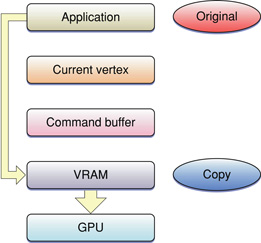
For static vertex data, you can use these extensions to cache the data in VRAM, which allows the data to utilize the full bandwidth of the graphics processor bus, as shown in Figure 8-5. Data needs to be copied to VRAM only once.
The next sections describe these extensions in more detail as well as the Apple fence extension (GL_APPLE_fence), which is used to synchronize drawing commands.
Vertex Array Range Extension
The vertex array range extension (APPLE_vertex_array_range) lets you define a region of memory for your vertex data. This allows the OpenGL driver to optimize memory usage by creating a single memory mapping for your vertex data. You can also provide a hint as to how the data should be stored: cached or shared. The cached option specifies to cache vertex data in video memory. The shared option indicates that data should be mapped into a region of memory that allows the GPU to access the vertex data directly using DMA transfer. This option is best for dynamic data. If you use shared memory, you'll need to double buffer your data. See “Double Buffering Vertex Data.”
You can set up and use the vertex array range extension by following these steps:
Enable the extension by calling
glEnableClientStateand supplying theGL_VERTEX_ARRAY_RANGE_APPLEconstant.Allocate storage for the vertex data. You are responsible for maintaining storage for the data.
Define an array of vertex data by calling a function such as
glVertexPointer. You need to supply a pointer to your data.Optionally set up a hint about handling the storage of the array data by calling the function
glVertexArrayParameteriAPPLE.GLvoid glVertexArrayParameteriAPPLE(GLenum pname, GLint param);
pnamemust beVERTEX_ARRAY_STORAGE_HINT_APPLE.paramis a hint that specifies how your application expects to use the data. OpenGL uses this hint to optimize performance. You can supply eitherSTORAGE_SHARED_APPLEorSTORAGE_CACHED_APPLE. The default value isSTORAGE_SHARED_APPLE, which indicates that the vertex data is dynamic and that OpenGL should use optimization and flushing techniques suitable for this kind of data. If you expect the data to be static supply,STORAGE_CACHED_APPLEso that OpenGL uses VRAM caching and other techniques to optimize memory bandwidth.Call the OpenGL function
glVertexArrayRangeAPPLEto establish the data set.void glVertexArrayRangeAPPLE(GLsizei length, GLvoid *pointer);
lengthspecifies the length of the vertex array range. The length is typically the number of unsigned bytes.*pointerpoints to the base of the vertex array range.Draw with the vertex data using standard OpenGL vertex array commands.
Call
glFlushVertexArrayRangeAPPLE.void glFlushVertexArrayRangeAPPLE(GLsizei length, GLvoid *pointer);
lengthspecifies the length of the vertex array range, in bytes.*pointerpoints to the base of the vertex array range.For dynamic data, each time you change the data, you need to maintain synchronicity by calling
glFlushVertexArrayRangeAPPLE. You supply as parameters an array size and a pointer to an array, which can be a subset of the data, as long as it includes all of the data that changed. Contrary to the name of the function,glFlushVertexArrayRangeAPPLEdoesn't actually flush data like the OpenGL functionglFlushdoes. It simply makes OpenGL aware that the data has changed.To make sure that your data is fully coherent, in addition to calling
glFlushVertexArrayRangeAPPLEafter drawing and prior to modifying the data, you need either to callglFinishor to set up a fence. TheAPPLE_fenceextension lets you set up selective synchronization. See “Fence Extension” and “Double Buffering Vertex Data.”
Listing 8-1 shows code that sets up and uses the vertex array range extension with dynamic data. It overwrites all of the vertex data during each iteration through the drawing loop. The call to the glFinishFenceAPPLE command guarantees that the CPU and the GPU don't access the data at the same time. Although this example calls the glFinishFenceAPPLE function almost immediately after setting the fence, in reality you need to separate these calls to allow parallel operation of the GPU and CPU. To see how that's done, read “Double Buffering Vertex Data.”
Listing 8-1 Using the vertex array range extension with dynamic data
// To set up the vertex array range extension |
glVertexArrayParameteriAPPLE(GL_VERTEX_ARRAY_STORAGE_HINT_APPLE, GL_STORAGE_SHARED_APPLE); |
glVertexArrayRangeAPPLE(buffer_size, my_vertex_pointer); |
glEnableClientState(GL_VERTEX_ARRAY_RANGE_APPLE); |
glEnableClientState(GL_VERTEX_ARRAY); |
glVertexPointer(3, GL_FLOAT, 0, my_vertex_pointer); |
glSetFenceAPPLE(my_fence); |
// When you want to draw using the vertex data |
draw_loop { |
glFinishFenceAPPLE(my_fence); |
GenerateMyDynamicVertexData(my_vertex_pointer); |
glFlushVertexArrayRangeAPPLE(buffer_size, my_vertex_pointer); |
PerformDrawing(); |
glSetFenceAPPLE(my_fence); |
} |
Listing 8-2 shows code that uses the vertex array range extension with static data. Unlike the setup for dynamic data, the setup for static data includes using the hint for cached data. Because the data is static, it's unnecessary to set a fence.
Listing 8-2 Using the vertex array range extension with static data
// To set up the vertex array range extension |
GenerateMyStaticVertexData(my_vertex_pointer); |
glVertexArrayParameteriAPPLE(GL_VERTEX_ARRAY_STORAGE_HINT_APPLE, GL_STORAGE_CACHED_APPLE); |
glVertexArrayRangeAPPLE(array_size, my_vertex_pointer); |
glEnableClientState(GL_VERTEX_ARRAY_RANGE_APPLE); |
glEnableClientState(GL_VERTEX_ARRAY); |
glVertexPointer(3, GL_FLOAT, stride, my_vertex_pointer); |
// When you want to draw using the vertex data |
draw_loop { |
PerformDrawing(); |
} |
For detailed information on this extension, see the OpenGL specification for the vertex array range extension.
Vertex Buffer Object Extension
The vertex buffer object extension (GL_ARB_vertex_buffer_object) can be used along with vertex arrays to improve the throughput of static or dynamic vertex data in your application. A buffer object is a chunk of memory. You can read and write directly to this memory using OpenGL calls such as glBufferData, glBufferSubData, and glGetBufferSubData or you can access memory through a pointer, an operation referred to as mapping a buffer.
You can set up and use the vertex buffer object extension by following these steps:
Call the function
glBindBufferARBto bind an unused name to a buffer object. After this call, the newly created buffer object is initialized with a memory buffer of size zero and a default state. (For the default setting, see the OpenGL specification for ARB_vertex_buffer_object.)void glBindBufferARB(GLenum target, GLuint buffer);
targetmust be set toGL_ARRAY_BUFFER_ARB.bufferspecifies the unique name for the buffer object.So that you can use vertex arrays with the vertex buffer object, enable the vertex array by calling
glEnableClientStateand supplying theGL_VERTEX_ARRAYconstant.Define an array of vertex data by calling a function such as
glVertexPointer. You need to supply an offset into your data buffer.Create and initialize the data store of the buffer object by calling the function
glBufferDataARB. Essentially, this call uploads your data to the GPU.void glBufferDataARB(GLenum target, sizeiptrARB size,
const GLvoid *data, GLenum usage);
targetmust be set toGL_ARRAY_BUFFER_ARB.sizespecifies the size of the data store.*datapoints to the source data. If this is notNULL, the source data is copied to the data store of the buffer object. IfNULL, the contents of the data store are undefined.usageis a constant that provides a hint as to how your application plans to use the data store. You can supply any of nine constants defined by the OpenGL specification. OpenGL uses the hint to optimize performance, not to constrain your use of the data. You'll see two of these constants in the examples that follow:GL_STREAM_DRAW_ARB, which indicates that the application plans to draw with the data repeatedly and to modify the data, andGL_STATIC_DRAW_ARB, which indicates that the application will define the data once but use it to draw many times.Map the data store of the buffer object to your application address space by calling the function
glMapBufferARB.void *glMapBufferARB(GLenum target, GLenum access);
targetmust be set toGL_ARRAY_BUFFER_ARB.accessindicates the operations you plan to perform on the data. You can supplyREAD_ONLY_ARB,WRITE_ONLY_ARB, orREAD_WRITE_ARB.Write the vertex data to its destination.
When you no longer need the vertex data, call the function
glUnmapBufferARB. You must supplyGL_ARRAY_BUFFER_ARBas the parameter to this function.
Listing 8-3 shows code that uses the vertex buffer object extension for dynamic data. This example overwrites all of the vertex data during every draw operation.
Listing 8-3 Using the vertex buffer object extension with dynamic data
// To set up the vertex buffer object extension |
#define BUFFER_OFFSET(i) ((char*)NULL + (i)) |
glBindBufferARB(GL_ARRAY_BUFFER_ARB, myBufferName); |
glEnableClientState(GL_VERTEX_ARRAY); |
glVertexPointer(3, GL_FLOAT, stride, BUFFER_OFFSET(0)); |
// When you want to draw using the vertex data |
draw_loop { |
glBufferDataARB(GL_ARRAY_BUFFER_ARB, bufferSize, NULL, GL_STREAM_DRAW_ARB); |
my_vertex_pointer = glMapBufferARB(GL_ARRAY_BUFFER_ARB, GL_WRITE_ONLY_ARB); |
GenerateMyDynamicVertexData(my_vertex_pointer); |
glUnmapBufferARB(GL_ARRAY_BUFFER_ARB); |
PerformDrawing(); |
} |
Listing 8-4 shows codes that uses the vertex buffer object extension with static data.
Listing 8-4 Using the vertex buffer object extension with static data
// To set up the vertex buffer object extension |
#define BUFFER_OFFSET(i) ((char*)NULL + (i)) |
glBindBufferARB(GL_ARRAY_BUFFER_ARB, myBufferName); |
glBufferDataARB(GL_ARRAY_BUFFER_ARB, bufferSize, NULL, GL_STATIC_DRAW_ARB); |
GLvoid* my_vertex_pointer = glMapBufferARB(GL_ARRAY_BUFFER_ARB, GL_WRITE_ONLY_ARB); |
GenerateMyStaticVertexData(my_vertex_pointer); |
glUnmapBufferARB(GL_ARRAY_BUFFER_ARB); |
glEnableClientState(GL_VERTEX_ARRAY); |
glVertexPointer(3, GL_FLOAT, stride, BUFFER_OFFSET(0)); |
// When you want to draw using the vertex data |
draw_loop { |
PerformDrawing(); |
} |
For detailed information on this extension, see the OpenGL specification for the vertex buffer object extension.
Fence Extension
The fence extension (APPLE_fence) is designed to synchronize drawing commands with modifications that you make to vertex data. A fence is a token used to mark the current point in the command stream. When used correctly, it allows you to ensure that drawing with a range of vertex array data (whether it's the entire set or a subset) is complete before you modify the data. When you use the fence you must synchronize the data.
This extension was created because the OpenGL commands glFlush and glFinish don't offer the level of granularity that is often needed to synchronize drawing and data modifications. A fence can help you coordinate activity between the CPU and the GPU when they are using the same resources. You'll want to use a fence when you are using the vertex array range extension for dynamic data. You do not need to use a fence for vertex buffer objects, but you do need to use a fence when you use the vertex array range extension and the shared memory hint.
Follow these steps to set up and use a fence:
Set up the fence by calling the function
glSetFenceApple. This function inserts a token into the command stream and sets the fence state tofalse.void glSetFenceAPPLE(GLuint fence);
fencespecifies the token to insert. For example:GLint myFence = 1;
glSetFenceAPPLE(myFence);
Wait for all OpenGL commands issued prior to the fence to complete by calling the function
glFinishFenceApple.void glFinishFenceAPPLE(GLuint fence);
fencespecifies the token that was inserted previously. For example:glFinishFenceAPPLE(myFence);
There is an art to determining where to insert a fence in the command stream. If you insert a fence for too few drawing commands, you risk having your application stall while it waits for drawing to complete. You'll want to set a fence so your application operates as asynchronously as possible without stalling.
The fence extension also lets you synchronize buffer updates for objects such as vertex arrays and textures. For that you call the function glFinishObjectAPPLE, supplying an object name along with the token.
For detailed information on this extension, see the OpenGL specification for the Apple fence extension.
Double Buffering Vertex Data
When you use the vertex array range extension and the shared memory hint, the GPU reads data directly from memory managed by your application. To avoid having the GPU and your application access the data at the same time, you'll need to synchronize access. A simple approach is for your application to operate on the vertex array data, flush it to the GPU, and wait until the GPU is finished before working on the data again. This is what Figure 8-6 shows.
To ensure that the GPU is finished executing commands before the CPU sends more data, you can insert a token into the command stream and use that to determine when the CPU can touch the data again, as described in “Fence Extension.” Figure 8-6 uses the fence extension command glFinishObject to synchronize buffer updates. Notice that when the CPU is processing data, the GPU is waiting. Similarly, when the GPU is processing data, the CPU is waiting. In other words, the application executes synchronously. A more efficient way is for the application to double buffer your data so that you can use the waiting time to process more data.
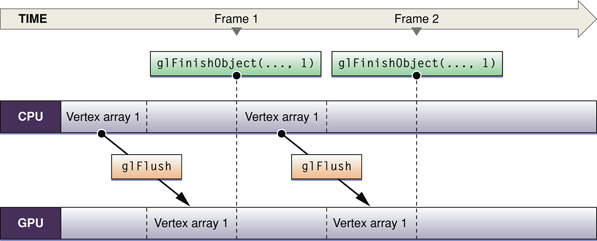
To double buffer your data, you must supply two sets of data to work on. Notice in Figure 8-7 that while the GPU is operating on one set of vertex array data, the CPU is processing the next. After the initial startup, neither processing unit is idle. Using the glFinishObject function provided by the fence extension, as shown, ensures that buffer updates are synchronized

See Also
OpenGL extension specifications:
OpenGL sample code projects (Sample Code > Graphics & Imaging > OpenGL):
Vertex Optimization demonstrates different ways to optimize vertex programs.
VertexPerformanceTest shows slow and fast vertex data paths.
VertexPerformanceDemo measures triangle throughput and compares different coding methods.
© 2004, 2008 Apple Inc. All Rights Reserved. (Last updated: 2008-06-09)